SDM ile müşteriler pek çok sorununa çözüm bulabilmektedir. Zamanı geçmiş uygulamaların kontrollü bir şekilde emekli edilmesi, depolama cihaz maliyetlerinin azaltılması, operasyonel verimliliğin zenginleştirilmesi, yedekleme (“backup”) performansının artırılması, “search” ve “eDiscovery” işlevlerinin hızlandırılması bu ürünün müşteriye kazandıracağı fırsatlar olarak sayılabilir. Uygulama ekibinin yöneticisi gözüyle sürece baktığımız zaman, en büyük problemlerden birisi, eski uygulama ve veritabanı yapılarının hala artmaya devam etmesi ve bir şekilde büyüyen bu yapının kontrol altına alınamamasıdır. Bölüm yöneticileri, “etkili nasıl bir program ile uygulamaların ve veritabanlarının emekli edilmesi sağlanabilir” sorusunun cevabına çözüm aramaya çalışmaktadırlar. IT yöneticileri gözüyle sürece baktığımız zaman hızla artan verinin yönetim zorlukları karşımıza çıkmaktadır. Depolama cihaz maliyetlerini azaltmak zorunda oldukları gibi verimliliği sağlamak ve uygulama performansını da artırmak durumundadırlar. CCO veya CLO gözüyle sürece baktığımız zaman, eski veritabanlarının yönetimiyle ilgili yaşanabilir sıkıntıları ortadan kaldırmaya dönük aksiyonlar almak zorundadırlar. Eski verilerin acaba legal kontrol için incelenmeleri gerekiyor mu, etkili bir şekilde riskler ne şekilde yönetilebilir ve kontrol altında tutulabilir, regülasyonlara uyum için kontrol edilmesine artık gerek olmayan veri ne şekilde yönetilebilir gibi sorulara cevap aramaktadırlar.
Geleneksel yöntemlerle süreçlerini devam ettiren organizasyonlar pek çok zorluk yaşamaktadırlar. Bu zorluklar, üstel olarak verinin büyümesine ek olarak yaşam döngüsünü yönetecek kuralların da olmamasında ötürü TCO’ya devamlı eskale edilen depolama birimi maliyetlerinin aşırı artışı, veritabanlarının yönetimi ile ilgili artan maliyetler olacaktır. Elbette tüm bunların etkisi olarak servis seviyelerinde düşüşler yaşanacaktır. Uygulama performansında düşüşler, yedekleme (“backup”) ve yedekten (“restore”) geri dönüş sürelerinde artışlar oluşacaktır.
Geleneksel yöntemleri yıkan ve yeni, modern yöntemlerle süreçlerini yöneten organizasyonlar ise süreçlerinde pek çok iyileştirme sağlayacaklardır. En önemli kazançlardan birisi, verinin otomotize edilmiş bir süreç içerisinde kontrol altında tutulabilmesidir (istenen verinin hızlıca çekilebilmesi, doğrulanması ve silinmesi işlemlerinin otomotize edilmesi). Depolama birimi maliyetlerinin donanım, bakım ve yönetim işlerinin bütünüyle ilgili düşürülmesi sağlanır. Söz verilen SLA sürelerine uyabilmeyi garantileyecekleri gibi üretimin devamlılığını da bu şekilde sağlamış olacaklardır. Felaket kurtarma operasyonlarında ihtiyaç duyulan süreyi kısaltmış olurlar. Verinin görünürlülüğüne (“better visibility into”) hakimiyet artacağı gibi, proaktif olarak konsolidasyon süreçleri iyileşecek ve veriye erişimde önceki yaşadıkları zorlukları aşmış olacaklardır.
Müşteri gözüyle süreçleri değerlendirdiğimizde karşımıza çıkan zorlukları şu şekilde sıralayabiliriz. Güvenlik ve uyum kontrollerinin yapılması ve eski sistemleri yönetmekle ilgili bilgi birikiminin zamanla azalması gibi risklerin artması, bu zorluklardan ilkidir diyebiliriz. Gizli bir takım maliyetler yine söz konusudur. Örneğin “eDiscovery” ve tahkikat (“investigation”) gibi durumların ortaya çıkmasıyla oluşan maliyetleri bu tür maliyetler olarak düşünebiliriz. Artan geri dönüş süreleri, yavaş performansdan ötürü IT değerinin gerek iç müşteri gerekse dış müşteri gözünden düşmesi yine yaşanan en büyük sıkıntılardan birisidir. Bu zorluklarla müşterinin mücadele etmek zorunda kaldığı durumları, zamanı geçmiş uygulamaların kontrollü bir şekilde ortamdan ayrıştırılması, depolama birimi maliyetlerinin azaltılması, yedekleme (“backup”) performansının iyileştirilmesi, operasyonel verimliliğin artırılması şeklinde özetleyebiliriz. Peki bu yaşanan sıkıntıların kök nedenleri nedir? Öncelikle bu kök nedenlerin en önemlilerinden birisi verinin organizasyona ait iyi planlanmış kurallar ve uyumluluk gereklerine göre yönetilememesidir. IT kaynaklarının verimli kullanılmamasından kaynaklı olarak ortaya çıkan üretimdeki azalmalardır.
Buraya kadar sıraladığımız tüm bu zorlukları aşmak için HPE’nin “Structured Data Mamanagent” (SDM) çözümünü kullanabiliriz. Bize katacağı değerler neler olacaktır? Öncelikle üretim ortamında kullanılan veritabanınından inaktif veriyi alarak, performansı kararlı hale getirecektir. Yedeklenecek veri boyutunu küçülteceği için, yedek imajının boyutu minimuma indirgenmiş olacaktır. Veri kontrol altında tutulduğu ve sadece gereken veri üzerinde regülasyonalarla/kurallarla ilgili “ediscovery” ve tahkikat (“investigation”) yapılabileceği için, gizli maliyetlerin azalmasını sağlayacak, son kullanıcının verimliliğinin de artmasını sağlayacaktır. SDM’in organizasyona sağladığı faydaların en önemlilerinden birisi, inaktif veri boyutunun azaltılabilmesi ve %50 veya daha fazla orana varan seviyede klon verisi boyutunun indiregenebilmesidir. Veritabanı maliyetlerinin ve “eDiscovery”/tahkikat (“investigation”) maliyetlerinin azaltılması SDM’in yine sağlayacağı faydalar arasındadır.
Organizasyonların SDM çözümüne ihtiyaç duyduklarını ortaya çıkaracak aslında bir kaç soru vardır. Verinin büyüme hızı nedir? Bu büyümenin farklı veri türlerine göre dağılımı nasıldır? Veri türlerine göre ve kullanılan “repository” lere göre verinin büyüklüğü ne şekilde etkilenmektedir? Veri boyutu, tüm verileri sakladığınız için mi artmaktadır? Büyük veya gereksiz şişmiş veritabanlarınız yavaş mıdır? Bu yavaşlık, organizasyon için ne tür tehlikeleri, riskleri beraberinde getirmektedir ve kullanıcıları nasıl etkilemektedir? Veriye ulaşma zorunluluğunuzdan dolayı eski (“legacy”) uygulamalarınızı hala korumak zorunda mısınız? Bakım maliyetlerini azaltmak ve ihtiyaç duyulan depolama birimi büyüklüklerini azaltmak amaçlı eski uygulamalarınızı emekli etmek için akıllıca yollar arıyor musunuz? Yedeklemek için ihtiyaç duyulan maliyetler gereksiz şişmiş veritabanlarından dolayı artmakta mıdır? Inaktif veri miktarınızdan ötürü, yedekleme süreleri etkilenmekte midir? RPO ve RTO için planladığınız SLA sürelerini bu inaktif veri ne şekilde etkilemektedir?
Organizasyonları sayısal anlamda yaşadıkları sorunları ortaya çıkarmak için yine şu soruları sormaları ve cevaplamaları gerekmektedir. Daha öncesinde iş ihtiyaçlarını gidermek için ne oranda bir veri oluşturulmuştu? Şimdi ise sadece bir kişinin veya sınırlı sayıda bir kaynağın erişimi için mi bu veriler hala muhafaza edilmektedir? Sahip olduğunuz veriyi oranladığınızda, “inactive”, “legacy” ve “dark data” olarak nasıl bir oran ortaya çıkacaktır? Tüm veri boyutunun organizasyona maliyeti nedir? Gereksiz büyümüş veritabanlarına sahip uygulamalar için aktif SLA ler nedir? Uygulama ile ilgili sıkıntılar yaşadığınızda kaç kullanıcı bu durumdan etkilenmektedir? Bu etkinin oranizasyona ve kullanıcılara olan etkisinin maliyeti nedir? Özellikle eskiden kalan (“legacy”) uygulamalarınız için kaç tane veritabanı klonu yönetmek zorundasınız? GB başına veritabanı yönetimi için ortalama yıllık maliyetleriniz ne kadardır? Kaynak ve bütçe durumunuz yıllık olarak ne oranda ve ne şekilde bu zorluklardan etkilenmektedir?
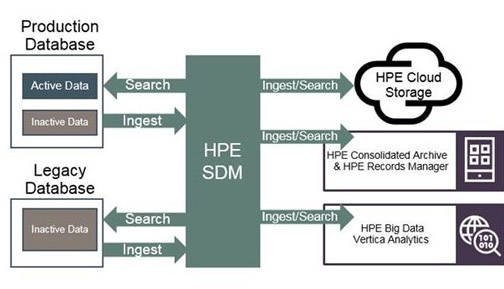
Eski ismi “HP Database Archiving” olan HPE SDM çözümünün biraz da teknik mimarisinden bahsedelim. Bu çözüm ile, esnek kurallar tanımlayarak yapısal verimizi yönetebiliriz. Çözüm sayesinde merkezi bir noktadan birden fazla sistem yönetimi yapılabilmektedir. Tekrar edilebilir şekilde otomasyon süreçlerini tanımlayabiliriz. Dizayn araçlarını ihtiyaçlarımızı karşılamak için kolaylıkla kullanabiliriz. Arşiv işlemini bir dosya veya bir veritabanına yapabiliriz. Gerektiğinde keşif işlemleri için (“search”) indekslenmiş yapısal veriyi kullanabiliriz. Arşiv verimize erişim imkanı sağlar. HPE SDM, herhangi bir bileşene ihtiyaç duymadan Oracle, MS SQL, Sybase, DB2 veritabanlarını destekler. Diğer veritabanları için jenerik JDBC bağlantıları sağlar. Oracle EBC ve Peoplesoft için ön tanımlanmış entagrasyon modülleri içerir. Aşağıdaki şekilde özet olarak desteklenen yapı bileşenleri görülmektedir.

Çözümün anahtar bileşenleri, yönetim konsolu (“Management Console”), Dizaynır (“Designer”), Lokasyonlar (“Locations”), Arşiv veriye erişimi (“Archive Access”) olarak sıralayabiliriz. Yönetim konsolu, tarayıcı (“browser”) tabanlı bir yapı sunar. Dizaynır ile geliştirme yapabilirsiniz. Lokasyonlar kısmında, çok geniş destek aralığına sahip arşiv lokasyonlarını kullanabilirsiniz. Arşiv veriye erişim özelliği sayesinde raporlama araçlarınızı, native uygulamaları kullanabilirsiniz.
Yönetim konsolunun (“management console”), tarayıcı tabanlı bir konsol olduğunu söylemiştik. Rol tabanlı güvenlik kullanabilirsiniz. Birden fazla ortamı yönetebilirsiniz. Güvenlik için Active Directory entegrasyonu yapabilirsiniz. Tanımlama, konfigürasyon, takvimleme ve yürütme işlemlerini yine bu konsol üzerinden yerine getirebilirsiniz. Tanımladığınız işlemleri monitör edebilirsiniz. Analitik değerleri görüntüleyebilirsiniz. Uygulamaları emekliye ayırmanıza imkan sağlayan araçları içerir. Arşiv veriniz için raporlama arabirimi sunar.
Dizaynır’ın (“Designer”) sağladığı görsel modelleme ortamı, iş ile ilgili işlemlerinizi (“transactions”) tanımlamanızı sağlar. “Data Movement”, “Data Extraction”, “Data Indexing” ve “Reporting” için modüller oluşturabilirsiniz. İş akışlarınız için görevler tanımlayabilirsiniz. Süreçlerinizle ilgili işleyiş dökümanlarını oluşturur.
Lokasyon (“locations”) özelliği sayesinde, veritabanı ortamınızdaki veriyi ayırabilirsiniz. Canlı arşiv işlemlerini yapabilirsiniz. Verinizi, yapısal dökümantasyon formatına (XML veya CSV) taşıyabilirsiniz. On-premise ve bulut tabanlı olmak üzere pek çok farklı arşiv cihazını destekler. Aşağıda olan şekilde SDM yapısını desteklenen lokasyonlarla birlikte özet şekilde görebiliriz.

Arşiv erişimi (“Archive Access”) sayesinde, aşağıdaki şekilden de görüleceği gibi kullanıcılar gerek arşivlenen gerekse aktif verilere erişim sağlayabilir. “Combined Reporting” olarak isimlendirilen yapıda veri arşiv veritabanında tutulur. “Combined Reporting”, Uygulama kopyasının, doğrudan üretim ortamındaki veritabanına bağlanması yerine “combined” olarak isimlendirilen arşiv veritabanına bağlanması için konfigürasyon yapılmasına imkan sağlar.

Arşiv erişimi (“Archive Acces”) ile dosyaya da arşiv alabileceğimizi söylemiştik. “Archive Query Server” dediğimiz yapı, verinin bir “file” içerisinde arşivlendiğini ifade eder. XML tabanlı arşivlerdeki veriye erişimi sağlayan standart data kaynakları sağlar. “Business Objects”, “Cagnos”, “Crystal” gibi raporlama araçları kullanılabilmektedir. Aşağıda olan şekil “Active Query Server” ın mimari içerisindeki yerini göstermektedir.

Aşağıda olan şekil de örnek bir mimariyi göstermektedir. Örnekte dağıtık bir yapı kullanılmıştır. Veri, ayrı bir “History” veritabanına arşivlenmektedir. Arşiv işlemi devam ederken, kullanıcılar aktif olarak çalışmaya devam edebilir. “Combined Reporting” sayesinde son kullanıcılar, raporlama ihtiyaçları için uygulamaya erişim sağlarlar. “Reload” işlemi de üretim ortamına verinin geri getirilmesi için kullanılabilir durumdadır.

Özet olarak, HPE Structured Data Manager (SDM) otomatik olarak bilginin yaşam döngüsünün yönetimini sağlar. Üretim ortamlarındaki ve eski sistemlerinizdeki inaktif veriyi taşıyarak yapısal verinizin optimizasyonunu sağlar. Bu işlemleri yaparken veri bütünlüğünü korur ve kullanıcı erişimlerini engellemez. SDM sayesinde, organizasyonlar, eski uygulamalarını otomatik bir sürece bağlayarak emekliye ayırabilir. Bu otomatik süreç, “extracting”, “validating” ve “deleting data” işlemlerinden oluşur. Bu çözüm, kapital harcamaları azaltacağı gibi, yönetimsel maliyetleri azaltır, kullanıcıların etkin ve verimli çalışmalarını sağlar. En önemlisi, legal ve uyumlulukla ilgili isteklere organizasyon çok daha hızlı dönüş yapabilir. Organizasyonların inaktif veriyi arşivleyebilmesi, zamanı geçmiş veritabanlarını ve ilişkili olduğu uygulamaları emekliye ayırabilmeye imkan verdiği için, SDM operasyonel verimliliği artırır. Bu operasyonel verimlilik organizasyonun analitik (“analytics”) işlemlerinden bilgi güvenliği (“Information Governance”) ve eDiscovery ihtiyaçlarına kadar tüm alanlardaki kalitesine yansır.
Burda yine önemli bir not eklemek istiyorum. Bir sonraki yazımda detaylarını aktarmaya çalışacağım “Structured Data Manager Test Data Management” çözümü ile test, development ve QA amaçlı veritabanları oluşturabilirsiniz. Bu çözüm sayesinde duyarlı verinizi belirleyebilir, sınıflamasını yapabilir, policy tabanlı data maskeleme özellikleriyle verinizi yeniden kimliklendirebilir ve test/development/QA de kullanılan üretim verinizi güvenli bir şekle getirebilirsiniz. Üretim verisinin kullanılamadığı durumlarda sentetik veri üreterek kullanamadığınız bu veri boşluklarını doldurabilir test/development/QA yapılarında üretim verisini, güvenli bir şekilde kullanabilecek hale getirebilirsiniz. Yine bu çözüm sayesinde test planı ihtiyaçlarınıza göre, daha küçük veri setleri oluşturarak gerek duyacağınız altyapı ihtiyaçlarınızı da minimum seviyeye indirgeyebilirsiniz. Test verisi ürütme işlemlerini tanımlayıp , tüm işlemleri belirledikten sonra bir web arayüzü ile tek bir dokunuşla test verisini yeniden üretebilir, mevcut olana ekleme de yapabilirsiniz. İsterseniz test verisi üretme işlemini bir takvime de bağlayabilirsiniz. Bu web arayüzü, test verisine ihtiyaç duyan birimin veritabanına hiç ulaşmadan kendi başına bir tıklama ile test verisini üretmesine de imkan vermektedir (Self Service).
Asiye Yiğit – 7 Agustos 2016
Leave A Comment