
Merhaba,
Uzun zamandır yeni bir yazı yazmadım. Açıkcası yeni bir yazı yazmak için ilgimi çekecek bir konu üzerinde düşünüyordum. Nihayet ilgili konuyu buldum. Bugün size “Red Hat OpenShift Data Science” çözümü hakkında bilgi aktarmaya karar verdim.
Öncelikle, veri biliminin hayatımızda gittikçe daha önemli bir hale geldiğinin hepimiz farkındayız. Nedeni aslında çok açık değil mi? Verilerin değeri gün geçtikçe artıyor. Veriden para kazanma yolları çok çeşitleniyor ve sonucu olarakta veriden değer üretmek son derece önemli bir hale geliyor. Southwest Airlines, verilerini etkin bir şekilde işlemesi sayesinde 100 milyon dolar tasarruf ettiğini söylüyor.
Veri bilimi sayesinde, bizler sorularımıza doğru cevaplar verebiliyor, yeni sorular oluşturabiliyor ve daha sağduyulu öngörülerle verileri doğru bir şekilde yorumlayarak kritik kararlarımızı net bir şekilde verebiliyoruz. Görüyoruz ki, verilerin dijital formata getirilmesi son derece elzemdir ki bu sayede çeşitli kaynaklardan aldığımız verileri zenginleştirerek en doğru kararları alabilmek için işleyebiliyoruz.
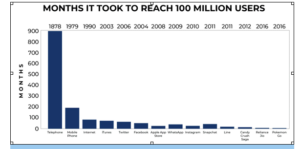
Hepimizin bildiği gibi, verilerimizi anlamlandırmak, organizasyonların gelecekteki belirsizlik korkusunu elbette azaltacaktır. Veri biliminin, özellikle son 2 yılda hızla arttığını gözlemlemekle birlikte, uzmanlar, hala emekleme döneminde olduğunu söylüyor. Bu demek ki gelecek çok ama çok daha farklı olacak hepimiz için. Sequoia Capital tarafından yayınlanan aşağıdaki grafik, 1878’den bu yana geleneksel pazarlama modellerinden sosyal medya tabanlı pazarlama tekniklerine geçişin, kullanıcı sayısında nasıl büyük bir farklılık gösterdeğini gözler önüne seriyor. Kaynakça bölümünde adreslerini ilettiğim makaleler, şöyle bir örnek veriyor. 2003 yılında iTunes, 100 ay içinde 100 milyon kullanıcıya ulaşırken, 2016 yılında Pokemon’un milyon kullanıcı sayısına ulaşması sadece günler sürdü. Elbette bu farklılık, veri içgörülerine güvenip dijitalleşmenin gücünü kullanarak tanıtım yapan platformlar sayesinde oluyor. Kendimden örnek vermem gerekirse, 2019’da ilk tekli çalışmam yayınlandı, “Cennet’in Firarisi”. İzlenme ve beğenme sayılarını arttırmak için, Google’ın yapay zeka ve makine öğrenme teknolojilerinin gücü, doğru kullanıcı gruplarına gösterimi sayesinde izlenme ve beğeni oranı çok arttı. Keza, geçen yıl çıkardığım ilk şiir kitabım için de, ne kadar etkin, akıllıca, doğru kullanıcı gruplarına dijital reklam yapılırsa, alım oranlarının o derece arttığını gördüm. Aslında, ilerlemeyi düşündüğümüz her alanda, müzik, kitap, iş, ne olursa olsun, marketin doğru analiz edilerek, doğru platformlarda, doğru kullanıcı gruplarıyla etkileşiminin sağlanmasının ne derece önemli olduğu açıktır. Bu sürecin en doğru şekilde ilerletilmesi de, şüphesiz verilerin anlamlandırılarak doğru kararların verilmesi, sürecin sürekli geliştirilmesine olanak sağlayarak, sonuçtan yine öğrenen ve kararlarını dinamik olarak değiştirebilen bir yapı ile mümkün olabilir.
Katıldığım pek çok sunumda, uzmanlar veri için, artık değerinin petrolü bile aştığını söylüyor. Günümüzde zilyonlarca bayt veri üretiliyor ve bu verinin deşifre edilerek kendimizin, firmamızın lehinde kullanarak iş modellerini geliştirmemiz, gerekiyorsa değiştirmemiz son derece kritiktir.
Diğer taraftan, bilim olmadan verinin bir anlamı da yoktur. Kökte yatan nedenleri ancak, bilim ile, uygun algoritmalarla ortaya çıkarabiliriz. Verilerin okunması, analiz edilmesi önemlidir. Elbette, kaliteli veriye sahip olmak, farklı verilerle zenginleştirerek bu veriyi nasıl anlamlandırabileceğimizi bilmek, veriye dayalı keşifler yapabilmemiz için yerine getirmemiz gereken daha pek çok şeyin yanında olmaz ise olmazlardandır.
Örneğin, gerçi ben, Pandemi sürecinin başlamasıyla kullanmaya başladım ama, e-ticaret sitelerini yoğun olarak kullanıyoruz. Dikkatimi çeken şey şu oluyor genelde, bu siteler, satın alma geçmişimize bakarak, kişiliklerimizi, nelere eğilimlerimizin olduğunu anlamaya çalışıyor ve doğru bir öneri sistemi oluşturmaya çalışıyor. İşte biz bu öneri sistemini ne kadar yapay zeka, makine öğrenmesi gibi teknolojilerle güçlendirebilirsek müşterimizi, karşısına çıkaracağımız opsiyonlarla da o derece cezbedebiliriz ve alım yapmasını sağlayabiliriz. Bazen gereksiz alım yapmamızın nedeni bu olsa gerek.
İş süreçlerimizin optimizasyonunda dahi son derece etkin rol oynayan veri bilimi, geleceğin, verinin doğru bir şekilde anlamlandırılmasıyla şekillendiğinde, çok daha yaşanabilir bir ortam olacağını gösteriyor. Örneğin, savaşın, dünyaya, nesillere bıraktığı etkiyi analiz eden, öğrenen bir yapay zeka, savaş çıkmaması için her türlü aksiyonu alırdı. Acıdır ki insan hala savaş konusunda ısrarcı.
Neyse konuyu dağıtmayayım, özetle geleceğimizi en etkin şekilde kurgulamamız, zaten verinin içinde barınıyor. Yeter ki doğru şekilde anlamlandıralım.
Bu kadar edebiyat yaptıktan sonra, gelelim, “Red Hat OpenShift Data Science” konusuna. ODS şeklinde kısaltarak yazıma devam edeceğim. ODS, “upstream” projesi olan “Open Data Hub”dan seçilen bir dizi bileşenden oluşturulan yönetilen bir bulut hizmetidir. ODS, AWS üzerinde “Red Hat OpenShift Service” veya “Red Hat OpenShift Dedicated” üzerinde tamamen yönetilen bir bulut hizmeti ortamı olarak sağlanır. “Red Hat OpenShift Dedicated”i biliyoruz, Amazon Web Services (AWS) ve Google Cloud üzerinde yönetilen bir “Red Hat OpenShift” servisidir.
Red Hat’in Kubernetes uzmanlığı sayesinde, geliştiriciler, deneysel modelleri daha hızlı ve daha az engelle üretim ortamına geçirebilirler. “Source to Image (S2I)” gibi temel OpenShift teknolojilerinden yararlanarak, modelleri kolay test için “OpenShift Dedicated” platformunda barındırabilir veya şirket içi, uç veya bulut uygulamalarında kullanılmak üzere konteyner şeklinde dışa aktarabilirler.
Amacı, veri bilimcilerinin makine öğrenimi, ML diye ifade edeceğim sonrasında, iş yüklerini geliştirebilecekleri, eğitebilecekleri, test edebilecekleri ve sonrasında da konteyner şeklinde dağıtabilecekleri kararlı, güvenli, sağlam bir sanal ortam sağlamaktır. Bu ne demek? Bu sayede, hızlı denemeler ve model geliştirmeler yapabileceğimiz için, geliştiriciler, modellerini daha az engelle karşılaşarak iş akışlarına entegre edebilirler.
ODS, JupyterLab arayüzünde, “Jupyter notebooks” sağlar. Beraberinde kutudan hazır çıkan pek çok imajda sağlar. Bu imajlar, yaygın kullanılan kitaplıkları, paketleri otomatik olarak içerir. Örneğin, TensorFlow, PyTorch, Scikit-learn, Pandas, Numpy gibi.
Daha da etkileyici olan, “Red Hat Marketplace”te bulunan çok çeşitli doğrulanmış iş ortağı veri bilimi ve makine öğrenimi araçları arasından da seçim yapabilirsiniz. Starburst, Anaconda, IBM Watson, Intel ve Seldon’dan yazılım ve SaaS tabanlı hizmetler alabileceğiniz gibi düzinelerce başka iş ortağı hizmetleri de bu yapıya entegre edilmiş durumdadır. Bu hizmetlerden de faydalanabilirsiniz.
Dikkat ederseniz, ODS, makine öğrenimi iş yükleri ve geliştirme iş akışları için tasarlanmış bir açık kaynak mimarisi üzerine kuruludur. Diğer bir önemli faydası, veri bilimi ile DevOps arasındaki boşlukları daraltarak üretim sürecindeki el değiştirme sancılarını da azaltmaktadır. Veri bilimcileri, Jupyter not defterlerinde gerçek zamanlı olarak çalışma yapar. Geliştiriciler, konteyner hazır modellerini daha az problemle akıllı uygulamalara entegre edebilir.
Aşağıdaki şekil, model operasyon yaşam döngüsünün ODS ile ortak bir platform olarak nasıl bütünleştiğini göstermektedir.

Açıktır ki, ODS sayesinde kuruluşlar, akıllı uygulama yolculuklarını hızlandırmak için denemelerini daha hızlı yapabilir, konusunda en iyi teknolojileri deneyimleyebilir. Dolayısıyla, veri bilimciler herhangi bir kısıtlayıcı araç olmadan seçim yapabilir ve sınırlamalar olmaksızın yeni veri içgörüleri oluşturabilirler.
Red Hat’in ürün geliştirme döngüsünün, her zaman açık kaynaklara ve Red Hat’in ürünlerine yön vermeye yardımcı olan topluluklara dayandığını biliyoruz. Fedora’nın Red Hat Enterprise Linux için “upstream” projesi olması gibi, aşağıda listelenen projeler de ODS’i oluşturan ürünlerin “upstream”leridir.
Open Data Hub
Jupyter
TensorFlow
PyTorch
Scikit-Learn
Kaynakça da linkini yazdığım video’da, “OpenShift Cluster Manager”dan, “Red Hat Marketplace”den alınan ODS’in “Add-Ons” olarak ne şekilde yüklendiğini, açıkcası tek bir klik ile, ardından ODS’in gösterge panelinden JupyterHUB’ın nasıl başlatıldığını, ne şekilde imaj seçildiğini, örnek bir python koduyla ne şekilde model geliştirildiğini görebilirsiniz. Bu video’da anlatılanların metin haline, Master NLP using Red Hat OpenShift Data Science | Red Hat Developer linkinden ulaşabilirsiniz. Siz kendiniz de yine bu adresten “OpenShift Developer Sandbox”ı çalıştırarak, metinde anlatılanları uygulamalı deneyimleyebilirsiniz.
Başlangıç yazısı olarak oldukça bilgilendirici bir yazı sunmaya çalıştım. Sonrası sizin hünerli ellerinize ve aklınıza kalıyor. Aşağıda olan linkler çok faydalı bilgiler içeriyor. İlk etapta 5 dakikalık video’yu izleyerek genel bir fikir edinip, ardından Sandbox’ta bu anlatılanları deneyipleyip, dökümanlarla bilginizi genişleterek, daha açık sulara doğru yelken açabilirsiniz. Sunulan platform son derece başarılı, etkin, güvenli ve tamamen açık. Sonrası artık sizin hayal gücünüzle şekillenecek. Geleceğimiz için verinin derinlerine inerek sağlıklı kararlar verecek yapıları oluşturmanız artık çok daha kolay.
Sarav Asiye Yiğit – 26 Kasım 2022 Cumartesi
Kaynakça:
Why Data Science Is Important And Why Do We Need It? (analytixlabs.co.in)
What Is Data Science Process and Its Significance? (analytixlabs.co.in)
Red Hat OpenShift Data Science
How Red Hat OpenShift Data Science fits in your AI/ML journey
Red Hat OpenShift Data Science Overview | Red Hat Developer
4 reasons to use Red Hat OpenShift Data Science | Red Hat Developer
Red Hat OpenShift Data Science: Cloud services for AI/ML
Preview demo of Red Hat OpenShift Data Science – YouTube
Master NLP using Red Hat OpenShift Data Science | Red Hat Developer
Unicorn Magic, Unicorn, Dreamy, Softness, Fairy, moon, fantasy, water, magical, HD wallpaper | Peakpx (Başlık Görseli)