
Günümüzde, şirketler her zamankinden daha fazla veri toplamak ve bu verileri farklı ihtiyaçları için saklamak zorundadır. Depolama sistemlerinin kapasitesi ve yoğunluğu artarken, şirketler de daha hızlı veri üretmekte ve sonucu olarakta daha fazla depolama alanına ihtiyaç duymaktadırlar. Verinin, kullanıcıların ihtiyaç duyduğu anda lokasyondan bağımsız ulaşılabilir olmasını sağlamak için etkin şekilde yönetilmesi ve korunması gerekmektedir. Artan veri hacmi, bu devasal hacmi yönetme ve koruma ihtiyacı, ilgili birimlere tahsis edilen bütçeleri aşmaktadır.
Artan depolama alanı ihtiyacının en önemli nedenlerinden birisi hiç şüphesiz ki, verilerin daha hızlı üretilmesine ve analiz edilmesine imkan sağlayan yeni teknolojilerin hayatımıza girmiş olmasıdır. Bulut ortamları, Software-Defined-Network yapıları, büyük ölçekli nesne tabanlı depolama alanları, büyük veri çözümleri bu teknolojilerden bazılarıdır. Depolama birimleri, bu yeni teknolojileri desteklemeli, hızlı bir şekilde ihtiyaçları karşılayabilmelidir.
“Software-Defined-Storage” olarak ifade edilen yazılım tabanlı depolama teknolojisi, endüstri satndardı x86/x64 mimarisi donanımı üzerinde, dağıtık yapıda çalışan yeni bir depolama altyapısı türü sağlar.
Yazılım tabanlı depolama teknolojisini, fiziksel depolama cihazları ve veri istekleri arasında soyutlama katmanı sağlayan bir yazılım katmanı olarak düşünebiliriz. Bu soyutlama katmanı, birçok depolama cihazının ve sunucunun sanal bir depolama alanında toplanmasını sağlar. Yazılım tabanlı bu teknoloji, pek çok farklı kaynaktan gelen depolama alanlarının sanallaştırılmasını kolaylaştırır. Ek olarak, bu sanal depolama alanları, esneklik ve hata toleransı sağlamak için yedekli olarak inşa edilebilirler. Bu teknolojinin sağladığı diğer önemli bir kazanç, siz ilk ihtiyacınızı belirleyerek yapıyı oluşturduktan sonra, olası süpriz yük ihtiyacını, ortama yeni sunucular ekleyerek doğrusal bir performans artışı ile sağlayabiliyor olmanızdır.
Red Hat tarafından sağlanan yazılım tabanlı depolama alanı Teknolojileri nedir diye bakacak olursak. Red Hat Ceph Storage ve Red Hat Gluster Storage, bu kapsamda karşımıza çıkan iki teknolojidir. Red Hat Ceph Storage, blok ve nesne tabanlı bir depolama alanı sağlarken; Red Hat Gluster Storage, dosya tabanlı bir depolama alanı sağlamaktdır. Gerçi, Ceph’in son sürümüyle, dosya tabanlı depolama alanı olarakta kullanılabileceği söylenmektedir.
Red Hat Ceph Storage, PB ölçekte, endüstri standardı donanımlar üzerinde ölçeklendirilebilen açık kaynaklı dağıtım bir depolama sistemidir. Native API, Amazon S3, OpenStack Swift API protokelleri üzerinden erişilebilir. OpenStack ortamları için imajları, sanal disk cihazlarını depolayabilir. Nesne tabanlı depolama alanına standart API leri kullanarak ulaşan uygulamalar için idealdir. Konteyner yapılar için kalıcı depolama alanı sağlamak amacıyla kullanılabilir. Zengin medya uygulamaları için kullanılabilir. Çok bölgeli (“multisite”) ve olağanüstü durum kurtarma merkezleri (“disaster recovery”) için seçenekler sunar. Veri sürekliliği için silme kodlaması (“erasure coding”) veya replikasyon imkanı sağlar. Esnek depolama birimi kuralları sağlar.
Ceph’in en önemli yeteneklerinden birisi, verileri Ceph depolama alanında ne şekilde sakladığıdır. RADOS (“Reliable Autonomic Distributed Object Store”) sistemi, verileri mantıksal depolama havuzlarında nesne olarak depolar ve bu nesnenin nerede depolanması gerektiğini otomatik olarak hesaplamak için CRUSH (“Controlled Replication Under Scalable Hashing”) veri yerleştirme (“data placement”) algoritmasını kullanır. Herhangi bir istemci bir nesnenin nerede olduğunu belirlemek için bu algoritmayı kullanabilir. Bu nedenle nesneyi bulmak için merkezi bir arama sunucusuyla iletişim kurmasına gerek olmaz. İstemci, nesneyi, bir Ceph sunucusuyla doğrudan iletişim kurarak alabilir. CRUSH algoritması, kümeleme (“cluster”) yazılımının, nesneleri otomatik olarak ölçeklendirmesine, yeniden dengelemesine, verileri korumasına ve hatalardan kurtulmasına olanak sağlar. Kurumsal olarak hazır (“enterprise ready”) bir çözümün sahip olması gereken özelliklere sahiptir.
Red Hat Ceph Storage mimarisi hangi bileşenlerden oluşur? Arkada RADOS olarak bilinen nesne tabanlı depolama alanı vardır. RADOS ile etkileşim kurmak için pek çok farklı erişim metoduna sahiptir. RADOS, kendi kendini onarabilen (“self-healing”) ve kendi kendini yönetebilen (“self-managing”) özelliklere sahiptir.
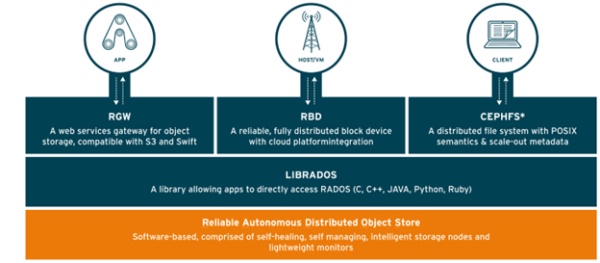
Şekil 1. Ceph Cluster RADOS Back end
RADOS, ihtiyaç duyduğunuz mimariye göre ölçeklendirilebilen aşağıda olan “daemon”ları içerir.
“Monitors (MONs)”: ”Cluster”ın durumunun haritasını tutar ve diğer “daemon”ların birbirleriyle koordinasyonuna yardımcı olur.
“Object Storage Devices (OSDs)”: Veriyi depolayan, veri replikasyonunu sağlayan, verinin kurtarılması ve yeniden dengelenmesi (“re-balancing”) sağlayan bileşendir.
“Managers (MGRs)”: Web tarayıcısı tabanlı gösterge tablosu ve REST API aracılığıyla “cluster”ın durumunu gösterir. Çalışma zamanı metriklerini takip eder.
“Metadata Servers (MDSs)”: İstemciler tarafından POSIX komutlarının verimli bir şekilde yürütülmesine izin vermek amacıyla CephFS tarafından kullanılan (ancak nesne tabanlı depolama veya blok tabanlı depolama değil) meta verisini depolar.
Ceph Nesne Depolama Cihazları (OSD), bir Ceph depolama “cluster”ın yapı taşlarıdır. OSD’ler bir depolama cihazını (sabit disk veya başka bir blok cihaz gibi), Ceph depolama “cluster”ına bağlar. Tek bir depolama sunucusu birden çok OSD programı çalıştırabilir ve “cluster”a birden fazla OSD sağlayabilir.
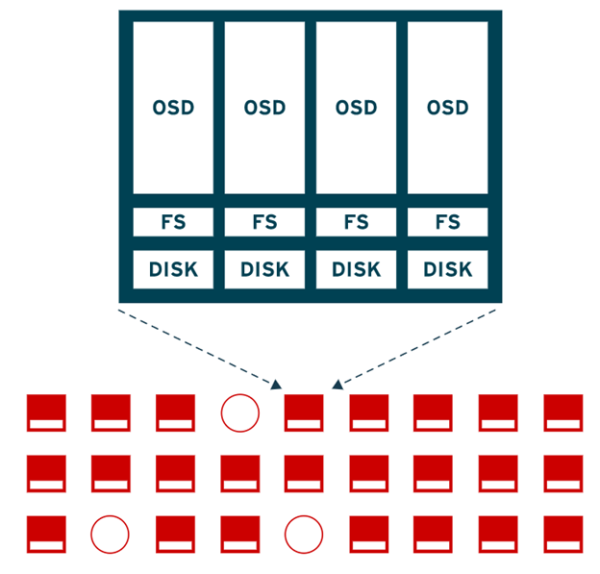
Şekil 2. OSD node detayı
Şekil 2.’yi detaylı açıklamam gerekiyor. Şekilde gördüğünüz kare kırmızı kutular, “cluster”a OSD sağlayan sunuculardır. Kırmızı yuvarlak olan şekiller ise “monitor”leri temsil etmektedir. En üstte, ortadaki sunucunun detaylı görünümünde, 4 disk tarafından beslenen 4 adet OSD’yi “cluster”a sağladığını görüyoruz. Her birinde dosya sistemi yapısı oluşturulduğuna dikkat edin.
Her bir OSD, Ceph “cluster”ına bir depolama cihazı sağlar. Normalde, her depolama cihazı normal bir dosya sistemiyle yapılandırılabilir. Red Hat Ceph Storage şu anda yalnızca XFS dosya sistemini desteklemektedir. Genişletilmiş öznitelikler (“xattrs”), dahili nesne durumu (“internal object state”), snapshot meta verisi ve Ceph RADOS ACL’ler hakkında bilgi depolamak için kullanılır. Genişletilmiş öznitelikler, XFS dosya sisteminde varsayılan (“default”) olarak etkindir.
Red Hat Ceph Storage 2, RADOS’ta veri depolamak için “BlueStore” adlı yeni bir özellik sunmaktadır. OSD depolama cihazlarının bir dosya sistemiyle yapılandırılması yerine, BlueStore yerel depolama cihazlarını “raw” modda kullanır.
OSD’lerin genel tasarım amacı, “cluster”ın en yüksek verimlilikte çalışmasını sağlamak için işlem gücünü, fiziksel verilere mümkün olduğunca yakınlaştırmaktır. CRUSH algoritması, nesneleri OSD’lerde saklamak için kullanılır.
Nesnelerin birden fazla OSD’ye replikasyonu (“çoğaltılması”) otomatik olarak gerçekleştirilir. Bir OSD, nesnenin yerleşim grubu (“placement group”) için birincil OSD’dir. Ceph istemciler, verileri okurken veya yazarken her zaman birincil OSD ile iletişim kurar. Diğer OSD’ler, ikincil OSD’lerdir ve “cluster”da oluşabilecek arızalar durumunda verilerin geri getirilmesinde önemli rol oynarlar.
Birincil OSD’nin Görevleri:
Tüm I/O istekleri
Verinin replikasyonu ve korunması
Verinin tutarlılığının kontrol edilmesi
Verinin yeniden dengelenmesi
Verinin geri getirilmesi
İkincil OSD’nin Görevleri:
Her zaman birincil OSD’nin kontrolü altında hareket eder
Birincil OSD olabilme yeteneğine sahiptir
Her OSD’nin kendi OSD “journal”ı vardır. OSD “journal”, dosya sistemi “journal”ı ile ilgili değildir. OSD’ye yazma işlemlerinin performansını artırmak için kullanılır.
Ceph istemcilerden gelen yazma isteklerinin doğası, “random”dır. Bu yazma istekleri, “OSD” daemon tarafından “journal”a, sıralı olarak yazılır. Bu sayede, host dosys sistemi, verimliliği artırmak amacıyla yazma işlemlerini birleştirmek için zaman kazanmış olur. Ceph “cluster”a gelen her yazma işlemi, OSD “journal” yazma işlemini tamamladıktan sonra, istemciye bildirilir. Ardından, OSD, operasyonu dosya sistemine yapar. Her birkaç saniyede, OSD, yeni gelen istekleri “journal”a yazmayı durdurur. Bunun nedeni, OSD “journal”in içeriğini dosya sistemine yazmasıdır. Sonrasında, dosya sistemine işlenmiş istekleri “journal”den temizleyerek, “journal” depolama cihazı alanının geri kazanılmasını sağlar.
Ceph OSD veya depolama sunucusu başarısız olursa, OSD, yeniden başlatıldığında, “journal” yeniden uygulanır. Uygulama dizisi, en son yapılan sonkron operasyondan sonra başlatılır. çünkü senkronize edilmiş “journal” kayıtları OSD’nin depolama alanına kaydedildiğinden dolayı, “journal”dan temizlenmiş olacaktır.
OSD “journal”lar, OSD “node”larında “raw” alanlar kullanır. OSD “journal”lar, performansa odaklı ve/veya yazma yoğun ortamlar için SSD gibi hızlı bir cihazda yapılandırılmalıdır.
Ceph “cluster”a erişmek için aşağıda olan yöntemler kullanılır.
Ceph Native API (librados): Ceph “cluster”ın yerel (“native) arabirimidir. Bu yerel arabirimi üzerinde konumlandırılan hizmet arabirimleri, Ceph Blok Cihazı, Ceph Nesne Ağ Geçidini (Ceph Object Gateway) ve Ceph Dosya Sistemini içerir.
Ceph Object Gateway: Amazon S3 ve OpenStack Swift uyumluluğu için RESTful API’dir. Ceph Nesne Ağ Geçidi (Ceph Object Gateway), RADOS Ağ Geçidi, RADOSGW veya RGW olarak da adlandırılır.
Ceph Block Device (RBD, librbd): Bu, RADOS nesne deposuna, blok cihazı benzeri arabirim sağlayan bir Python modülüdür. Her Ceph Blok Cihazı, bir RADOS Blok Cihazı, RBD (RADOS Block Device) görüntüsü olarak adlandırılır.
Ceph File System (CephFS, libcephfs): Ceph “cluster”ına, POSIX benzeri bir dosya sistemi arabirimi üzerinden erişim sağlar.
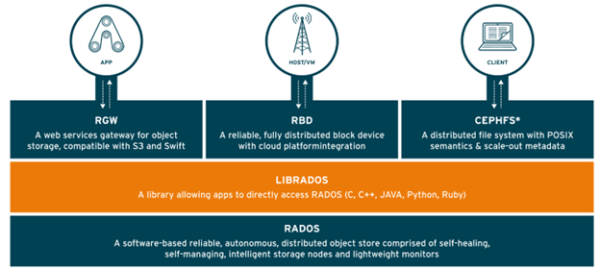
Şekil 3. Librados erişim yöntemleri
Ceph’de veri dağıtımı ve organizasyonu nasıl olmaktadır? Havuzlar (“pools”), nesneleri ortak bir ad etiketi altında saklamak için kullanılan Ceph depolama “cluster”ının mantıksal bölümleridir. Her bir havuza, nesneleri depolamak için belirli sayıda “hush buckets” atanır. “Hush bucket”lara, Yerleşim Grupları (“Placement Groups”) adı verilir.
Her bir havuza atanan yerleşim grubu (PG) sayısı, veri türüne ve havuza erişim için kullanılacak yönteme bağlı olarak yapılandırılabilir. Havuz oluşturulduğunda yapılandırılan yerleşim grubu (PG) sayısı, dinamik olarak artırılabilir, ancak hiçbir zaman azaltılamaz.
CRUSH algoritması, bir havuz için verilerin tutulacağı OSD’leri seçmek için kullanılır. Her havuza, yerleşim stratejisi için tek bir CRUSH kuralı atanır. CRUSH kuralı, hangi OSD’lerin veriyi depoladığını belirler.
Her istek için bir havuz adı belirtilmelidir. Her Ceph kullanıcısı için, ihtiyaca bağlı olarak, kümedeki tüm havuzlara veya belirli havuzlara izin verilir. Bu izinler okunabilir (“read”), yazılabilir (“write”) veya yürütülebilirdir (“execute”).
Yerleşim Grubu (PG), bir dizi nesneyi, “hush bucket” içine toplar. Yani, bir OSD grubuyla eşler. Bir nesne sadece bir PG’ye aittir ve aynı PG’ye ait tüm nesneler aynı “hash” sonucunu döndürür.
Bir nesne, CRUSH algoritması yardımıyla, nesne isminin “hash”ine bağlı olarak, PG ile eşleştirilir. Yerleştirme stratejisi, CRUSH yerleşim kuralı olarak bilinir. Yerleşim planı, hata etki alanine belirler. Hata etki alanı, CRUSH topolojisine göre seçilir. Bu etki alanı, replica veya “erasure code chunk”ı almak için kullanılır.
İstemci havuza bir nesne yazdığında, nesnenin yerleşim grubunu (PG) belirlemek için havuzun CRUSH yerleşim kuralını kullanır. Ardından istemci, hangi OSD’ye kopyanın yazılacağını belirlemek için, “cluster” eşlemesini, yerleşim grubu bilgisini ve CRUSH yerleşim kuralını kullanır.
Yerleştirme grubu tarafından sağlanan katman, Ceph “cluster”ına OSD’ler eklendiğinde önemlidir. Yeni OSD’ler bir “cluster”a eklendiğinde veya “cluster”dan çıkarıldığında, yerleşim grupları operasyonel OSD’ler arasında otomatik olarak yeniden dengelenir.
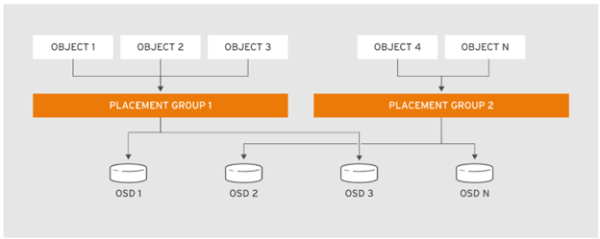
Şekil 4. Nesnelerin, OSD ile eşlenmesi.
Bir Ceph istemcisi, “cluster” haritasının en son kopyasını, “monitor”den alır. Bu, kümedeki tüm “MON”lar, “OSD”ler ve “MDS”ler ile ilgili bilgilerin. Elbette bu bilgi, nesnelerin nerede saklandığını söylemez; istemci erişmesi gereken nesnelerin konumunu hesaplamak için CRUSH kuralını kullanmalıdır.
Bir nesne için PG ID’nin hesaplanabilmesi için, istemci, nesne ID’sine (“object ID”) ve nesnenin depolama havuzu ismine ihtiyaç duyar. İstemci, “object ID“yi “hash”ler. “hash” mod “PG sayısı” formülü uygulanır. “PG ID” belirlendikten sonra, havuzun ismine göre, havuzun sayısal ID’sini arar. Daha sonra, “PG ID”ye, havuzun ID’sini ekler.
Bu bilgiler belirlendikten sonra, CRUSH algoritması kullanılarak PG’den sorumlu olan (“Acting Set”) OSD’ler belirlenir. “Acting Set” içinde o an aktif olan OSD’ler, “Up Set” olarak isimlendirilir. “Up Set” içinde olan ilk OSD, nesnenin yerleşim grubu için birincil OSD’dir. Bu set içindeki diğer OSD’ler, ikincil OSD’lerdir. Ceph istemcisi, nesneye erişmek için doğrudan birincil OSD ile çalışır. Şekil 5. üzerinden bu algoritmayı anlamaya çalışalım.
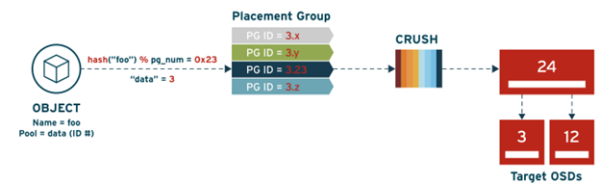
Şekil 5. Nesnenin, OSD ile eşlenme süreci.
Şekil 5.’de, nesnenin ID’si, “foo”, “hash”leniyor. Ardından, PG sayısı ile (“pg_num”) mod işlemi yapılıyor. “PG ID”, 3.23 olarak belirlendikten sonra, CRUSH algoritması ile PG’den sorumlu OSD’ler belirleniyor. İlk OSD, birincil OSD olarak alınıyor ve istemci doğrudan birincil OSD ile çalışıyor.
Sanırım biraz karışık oldu ama ikinci bölümde bu kısmı biraz daha açmaya çalışacağım. Şimdi Red Hat Ceph Storage’ı nasıl yapılandıracağız sorusunu cevaplayalım. https://access.redhat.com/documentation/en-us/red_hat_ceph_storage/ dökümanının öncelikle okunmasını öneriyorum. Red Hat Ceph Storage: Supported configurations. Makalesi mutlaka incelenmelidir. PoC çalışması için daha ufak bir ortam ile başlanabilir fakat Red Hat, üretim ortamları için aşağıda olan gereklilikleri şart koşmaktadır.
MON daemon için en az üç ayrı host olmalıdır.
DAS kullanan en az 3 tane OSD host olmalıdır.
En az iki tane ayrı MGR node olmalıdır.
Replika sayısı kadar en az OSD düşünülmelidir.
CephFS kullanılacaksa, eş olarak konfigürasyonu yapılmış en az iki tane ayrı MSD node olmalıdır.
Ceph Object Gateway kullanılacaksa en az iki tane ayrı RADOSGW olmalıdır.
Ansible Playbook ile Ceph-ansible paketini çalıştırabileceğimiz bir tane deployment node olmalıdır.
Yazım oldukça uzadı. Bu nedenle kurulum ve konfigürasyonla ilgili kısımları ikinci bölümde anlatıyor olacağım.
Asiye Yiğit – 1 Mart 2020 – Pazar