
Kafka Serisi – Genel Kavramlar
Merhabalar,
Geçmişe dönüp Kafka ile ilgili ben neler yazmışım diye araştırma yaptığımda bu konuyla ilgili ilk makalemi, 12 Haziran 2019 tarihinde yazdığımı gördüm.
Daha önce yazdığım bu makalede Apache Kafka’yı genel hatlarıyla ele aldım. O makalede Kafka’nın temel yapı taşlarını, nasıl çalıştığını ve hangi alanlarda kullanıldığını anlatmaya çalıştım. Kafka’nın bir mesajlaşma sistemi olarak nasıl veri akışını yönettiğini, topics, producers, consumers ve brokers gibi temel kavramları açıkladım. Kafka, partition yapısı sayesinde aynı topic üzerindeki mesajları birden fazla tüketiciye paylaştırarak paralel tüketimi destekler. Ancak, veriyi işleyen Kafka değil, Kafka’dan okuma yapan tüketicilerdir.Netflix, Uber ve LinkedIn gibi şirketlerin Kafka’yı nasıl kullandığını da örneklerle aktardım.
Bu makalede, temel bilgiler üzerinden bir altyapı oluşturarak, Kafka’nın neden bu kadar güçlü bir teknoloji olduğunu anlatmayı hedeflemiştim. Eğer okumadıysanız, önce o yazıya göz atmanızı tavsiye ederim. https://asiyeyigit.com/kafka-cluster/
Bu yazımda, hiç bilmeyen bir kişi için temel kavramların çok anlaşılır olmadığını farkettim. Dolayısıyla bugün, Kafka’yı sıfırdan ele alarak daha somut örneklerle anlatmak istiyorum.
Kafka’yı basitçe anlatmam gerekirse, verinin akışını yöneten bir trafik polisi gibi düşünebilirsiniz. Bir tarafta veriyi üreten kaynak sistemler var, diğer tarafta bu veriyi tüketen hedef sistemler. Kafka, bu iki taraf arasında bir köprü kurar ve verinin düzgün, hızlı ve güvenilir bir şekilde akmasını sağlar.
Örneğin, bir e-ticaret sitesindesiniz ve alışveriş yapıyorsunuz. Yaptığınız her tıklama, ürün arama veya sepet ekleme işlemi bir veri oluşturur. Kafka, veriyi üreticilerden (producers) alır ve sıralı bir şekilde saklar. Ancak, Kafka tüketicilere (consumers) veriyi aktif olarak iletmez; tüketiciler Kafka’dan veriyi çeker (pull yöntemi). Ancak, veriyi düzenleme veya işleme görevini üstlenmez. Bu görev, Kafka’dan veriyi okuyan tüketici sistemlere aittir (örneğin Elasticsearch, Flink, Spark gibi sistemler).
Kafka’nın kullanım alanları o kadar geniş ki, hemen her sektörde bir şekilde karşınıza çıkabilir. İşte birkaç somut örnek:
Gerçek Zamanlı Öneri Sistemleri: Netflix, izlediğiniz dizilere göre size yeni içerikler önerir. Kafka, bu öneri sistemleri için veriyi toplamak ve taşımak amacıyla kullanılır. Ancak, öneri algoritmalarını çalıştıran ve veriyi işleyen Kafka değil, Kafka’dan veriyi çeken büyük veri sistemleri (örneğin, Spark, Flink veya ML modelleri) gibi sistemlerdir.
Araç Takip Sistemleri: Uber, sürücülerin ve kullanıcıların konum verilerini toplar ve eşleştirir. Kafka, bu veriyi toplamak, taşımak ve sıralı bir şekilde depolamak için kullanılır. Ancak, konum verilerini analiz eden ve eşleştiren sistemler Kafka’dan veriyi çeken tüketici (consumer) sistemleridir.
Log Yönetimi: Kafka, bir log yönetim aracı değildir; ancak dağıtık bir commit log (distributed commit log) mekanizması olarak çalışır. Fluentd, Logstash veya Filebeat gibi araçlar, Kafka’yı logları taşımak için kullanabilir. Ancak, Kafka’nın rolü logları analiz etmek veya indekslemek değildir; Kafka yalnızca log akışını yöneten bir mesaj kuyruğu sistemidir. Kafka’nın temel rolü, logları saklamak veya analiz etmek değil, logları taşıyan ve sıralı şekilde depolayan bir mesaj kuyruğu olmaktır. Ancak, log analizi veya işleme işlemleri Kafka tarafından değil, Kafka’dan veri çeken sistemler (örneğin, Elasticsearch, Splunk veya Logstash) tarafından yapılır. Kafka, veriyi belirlenen retention policy kurallarına göre saklar. Retention süresi, belirli bir zaman aralığına (örneğin 7 gün) veya toplam disk kapasitesine (örneğin 100 GB) bağlı olarak ayarlanabilir. Kafka, belirlenen süre veya kapasite dolduğunda en eski mesajları otomatik olarak siler. Ancak, veriyi organize etmek veya yönetmek gibi aktif bir işlevi yoktur. Bu tür işlemler, Kafka’dan veri çeken sistemler (örneğin veri ambarları veya analitik platformlar) tarafından gerçekleştirilir.
Kafka’nın temel bileşenlerini anlamadan, sistemin nasıl çalıştığını kavramak zor olabilir. Şimdi bu bileşenlere ve onların görevlerine göz atalım:
Topic (Konu Başlığı)
Kafka’da veriler, “topics” denilen kategorilere ayrılır.
Örneğin:
Siparişler: Kullanıcıların verdiği siparişlerle ilgili veriler.
Arama Geçmişi: Kullanıcıların yaptığı ürün aramaları.
Veriyi üreten sistem (producer), mesajı belirli bir topic’e gönderir. Veriyi tüketen sistem (consumer) ise bu topic’ten mesajları okur.
Producer (Üretici)
Producer, Kafka’ya veri gönderen sistemdir.
Örneğin:
E-ticaret sitenizden sipariş bilgisi üretiliyor ve Kafka’ya gönderiliyor.
Bu, bir log dosyası, işlem kaydı ya da gerçek zamanlı bir veri akışı olabilir.
Consumer (Tüketici)
Consumer, Kafka’dan veri alan sistemdir.
Örneğin:
Analitik bir sistem, Kafka’dan aldığı verilerle rapor oluşturabilir.
E-posta servisi, Kafka’dan gelen sipariş bilgisine göre müşterilere sipariş onayı e-postası gönderebilir.
Broker (Aracı)
Kafka cluster’ındaki her bir düğüme (node) “broker” denir. Broker’lar, veriyi depolar ve ihtiyaç duyulduğunda tüketicilere sunar. Kafka’nın dağıtık yapısı sayesinde, veriler birden fazla broker arasında paylaştırılır. Bu, sistemin ölçeklenebilirliğini ve güvenilirliğini artırır.
Replika (yedekleme)
Kafka’da replika, verinin farklı broker’larda kopyalanarak saklanmasını sağlar. Eğer bir broker çökerse, veri kaybolmaz ve bir başka broker devreye girerek çalışmaya devam eder. Kafka cluster’ında her partition’ın bir lideri (leader) ve bir veya daha fazla yedek replikası vardır. Lider arızalanırsa, Kafka yeni bir lider seçerek sistemin sorunsuz çalışmasını sağlar.
Kafka, veriyi partition’lara böler ve ölçeklenebilirliği artırır. Ancak, Kafka’nın görevi yalnızca mesajları bölmek ve sıralı olarak saklamaktır. Gerçek paralel işlemeyi yapan Kafka değil, Kafka’dan veriyi çeken tüketici gruplarıdır (consumer groups). Bir consumer group içindeki tüketiciler, aynı topic içindeki farklı partition’lardan eşzamanlı olarak veri çekerek paralel işleme olanak tanır. Kafka, sadece mesajları belirli partition’lara dağıtarak, paralel işleme uygun bir yapı sağlar.
Partition Örneği:
Diyelim ki bir e-ticaret sitenizde bir gün içinde 1 milyon sipariş alıyorsunuz. Bu veriyi tek bir sistemin işlemesi zor ve yavaş olurdu, değil mi? İşte Kafka, bu siparişleri partition’lara bölerek farklı tüketicilere dağıtır. Ancak, siparişleri işleyen Kafka değil, Kafka’dan veriyi çeken tüketici sistemleridir (örneğin, sipariş işleme mikroservisleri veya veri analitik sistemleri). Kafka yalnızca veriyi bölerek yük dağılımını optimize eder ve paralel tüketimi mümkün kılar.
Offset:
Kafka, her mesajı bir offset ile etiketler, ancak offset yönetimi tüketicilere bağlıdır. Tüketiciler, Kafka’nın __consumer_offsets topic’inde saklanan otomatik offset yönetimini kullanabilir veya manuel olarak kendi offset sistemlerini geliştirebilirler. Kafka, offset bilgisini saklamak için bir sistem sunar, ancak offset’in ne zaman ve nasıl kullanılacağını tüketici belirler.
Bu bileşeni daha net anlamak için bir sinema bileti numarası benzetmesini yapabiliriz.
Diyelim ki 50 numaralı bileti aldınız ve koltuğunuza oturdunuz. Sonra bir süreliğine salondan çıktınız. Döndüğünüzde, 50 numaralı biletiniz olduğu için tam olarak nerede oturacağınızı bilirsiniz.
Kafka’da da offset, bir tüketicinin hangi mesajı okuduğunu ve nereden devam edeceğini belirler.
Partition ve offset konularını biraz daha somutlaştırmak istiyorum.
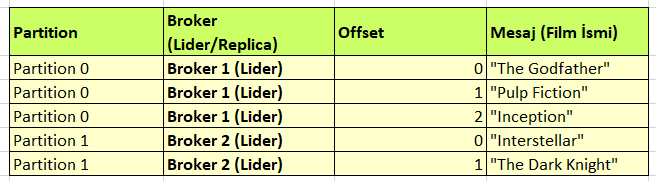
Diyelim ki “Amerikan Filmleri” adında bir topic oluşturduk ve bu topic tek bir partition içeriyor (Partition 0). Şimdi bu topic’e bazı mesajlar (film isimleri) gönderelim.

Bu tabloda olan bilgiler ne anlama geliyor?
Her mesaj, partition içinde bir sıraya sahip.
Her mesajın bir offset numarası var.
Offset 0’dan başlıyor ve her yeni mesajla birlikte 1 artıyor.
Kafka, aynı partition içindeki mesajların sırasını her zaman koruyor.
Pekala, bir consumer (tüketici) bu mesajları nasıl okur?
Diyelim ki bir tüketici bu topic’i okumaya başlıyor:
İlk başta, offset 0’dan başlayarak tüm mesajları sırasıyla okur:
“The Godfather” → “Pulp Fiction” → “Inception” → “Interstellar” → “The Dark Knight”
Tüketici 3. mesaja kadar okuduysa (offset = 2), Kafka bunu kaydeder.
Tüketici bir hata nedeniyle kapanırsa, tekrar açıldığında en son kaldığı offset’ten (offset = 3) okumaya devam eder.
Şimdi bu örnekte, partition sayısını iki yapalım, replication factor’ü ise 3 yapalım.
Replication Factor = 3 olduğundan, her partition’ın 2 kopyası var demektir.
Kafka bu partition’ları 3 farklı broker’a şu şekilde dağıtır:

Partition içindeki mesajlar ve offset değerleri ne olur?
Partition 0 ve Partition 1 içindeki mesajları yazalım.
Burada ne oluyor?
Partition 0’ın lideri Broker 1 → Kafka, mesajları önce Broker 1’e yazar.
Partition 0’ın replikaları Broker 2 ve Broker 3 → Broker 1 verileri yazdıktan sonra, Broker 2 ve Broker 3 bu verileri kopyalar.
Partition 1’in lideri Broker 2 → Kafka, Partition 1 mesajlarını önce Broker 2’ye yazar.
Partition 1’in replikaları Broker 3 ve Broker 1 → Broker 2 verileri yazdıktan sonra, Broker 3 ve Broker 1 kopyalar.
Kafka, esneklik ve hız söz konusu olduğunda oldukça başarılıdır.
- Hata Toleransı: Bir broker arızalansa bile Kafka, replikalar sayesinde veriyi kaybetmez.
- Düşük Gecikme: Kafka, veriyi anında taşır ve sıralı olarak depolar (çoğu durumda 10ms’den az gecikme ile). Ancak, veriyi işleyen Kafka değil, Kafka’dan veriyi çeken tüketici sistemlerdir.
- Ölçeklenebilirlik: Kafka, hem küçük hem de büyük veri akışlarını kolayca yönetebilir ve düşük gecikme ile taşıyabilir. Ancak, veriyi işleyen Kafka değil, Kafka’dan veriyi çeken tüketici sistemlerdir.
Şimdi Kraft hakkında konuşma zamanı geldi. Nedir Kraft? Ne işe yarar? Zookeeper’ın yerini mi aldı? Aradaki farkları nedir?
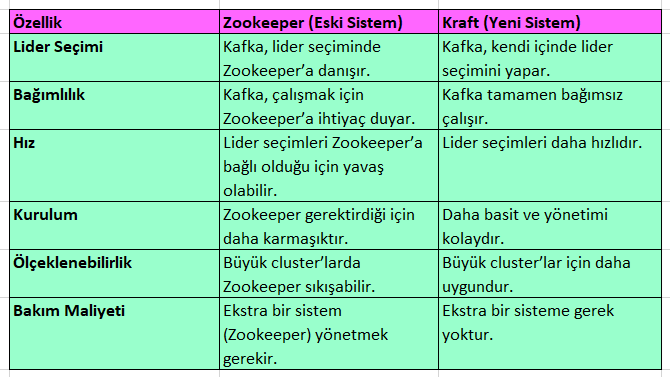
Kafka ekosisteminde büyük bir değişim yaşandı ve artık Kraft (Kafka Raft Mode), Kafka’nın metadata yönetimi ve lider seçim süreçlerini kendi içinde halletmesini sağlıyor. Eskiden bu iş Zookeeper tarafından yapılıyordu, ancak Kraft artık Kafka’yı daha hızlı, daha güvenilir ve bağımsız hale getiriyor.
Nedir Kraft?
- KRaft, Kafka Raft Konsensüs Algoritması (Kafka Raft Mode) anlamına gelir.
- Kafka’nın metadata yönetimini ve lider seçim sürecini kendi içinde çalıştırmasını sağlar.
- Zookeeper’a olan bağımlılığı ortadan kaldırır.
- Büyük ölçekli Kafka cluster’larının daha verimli yönetilmesini sağlar.
Kraft ne işe yarar?
- Kafka’nın yöneticisi gibi düşünebiliriz.
- Kafka, büyük bir organizasyon gibi çalışır:
- Üreticiler (Producers) mesaj gönderir.
- Tüketiciler (Consumers) mesajları okur.
- Broker’lar üreticilerden gelen mesajları alır, sıralı olarak saklar ve tüketiciler talep ettiğinde iletir. Kafka, veri işleme yapmaz, sadece verinin güvenilir ve düşük gecikmeli bir şekilde taşınmasını sağlar.
Ancak bu organizasyonun bir yöneticisi olması gerekir. İşte Kraft, Kafka’nın kendi yöneticisi olmasını sağlayan sistemdir. Eskiden Kafka, “Zookeeper” adında harici bir yöneticiden emir alıyordu. Artık Kafka kendi yöneticisi oldu ve Zookeeper’a ihtiyacı kalmadı.
Eğer hala anlaşılmadıysa, şöyle bir örneğin aklınızdaki soru işaretlerini kaldıracağını düşünüyorum.
Önce Zookeeper’lı Kafka (Eski Sistem)
Zookeeper’ı, Kafka’nın patronu olarak düşünelim.
Senaryo:
- Kafka’nın bir lider seçmesi gerektiğinde Zookeeper’a danışır.
- Broker’ların durumunu yönetmek için Zookeeper’a sürekli bilgi gönderir.
- Tüm Kafka broker’ları Zookeeper’a bağımlıdır.
Sorunlar:
- Ekstra bir sistem yönetmek gerekiyor (Zookeeper)
- Lider seçimleri biraz daha yavaş
- Ekstra donanım ve konfigürasyon maliyeti var
Kraft ile Kafka (Yeni Sistem)
Kraft’ı, Kafka’nın artık kendi kendini yöneten bir sistem haline gelmesi olarak düşünebiliriz.
Senaryo:
- Kafka artık kendi içinde lider seçebilir.
- Kafka broker’ları birbirleriyle direkt olarak iletişim kurar.
- Ekstra bir yönetime ihtiyacı yoktur, daha hızlıdır.
Avantajlar:
- Daha az sistem karmaşıklığı (Zookeeper gerekmiyor)
- Daha hızlı lider seçimleri
- Daha ölçeklenebilir bir yapı
- Daha basit kurulum ve Yönetim
Kafka için Kraft neden daha iyi?
- Kafka artık kendi liderlerini kendi seçebiliyor.
- Ekstra bir sistem (Zookeeper) yönetmek zorunda değiliz.
- Sistem daha hızlı çalışıyor ve daha az bakım gerektiriyor.
- Kurulumu ve ölçeklenmesi daha kolay.
Sonuç olarak Kafka ve Zookeeper farklarını içeren aşağıdaki gibi bir tablo oluşturabiliriz.
Kraft sayesinde Kafka artık tamamen bağımsız çalışabiliyor ve büyük ölçekli sistemler için iyi bir ölçeklenebilirlik sunuyor. Eğer Kafka’yı en iyi performansla kullanmak istiyorsanız, Kraft’a geçiş yapmayı ciddi şekilde düşünmelisiniz.
Kafka, gerçek zamanlı log taşımada kritik bir bileşendir. Ancak, logların analiz edilmesi ve işlenmesi Kafka’nın değil, Kafka’dan log verisini çeken sistemlerin (örneğin, Elasticsearch, Splunk, Logstash) görevidir.
Kafka, büyük miktarda veriyi yüksek hızda taşır ve sıralı bir şekilde depolar. Ancak, Kafka’nın görevi yalnızca veri akışını yönetmektir; veriyi işleyen, Kafka’dan veriyi çeken Flink, Spark, ksqlDB gibi sistemlerdir. Özetle, Kafka, gerçek zamanlı olayları (events) toplar, sıralar ve tüketicilere (consumers) iletir. Bunu Amazon gibi bir e-ticaret sitesindeki müşteri hareketlerini izleyen bir sistem üzerinden somutlaştıralım.
Örnek Senaryo: Kafka ile Gerçek Zamanlı Veri Akışı
Bir e-ticaret sitesi (Amazon gibi) düşünelim. Müşteriler siteyi ziyaret ediyor, ürünlere bakıyor, sepetine ekliyor ve satın alıyor. Tüm bu olaylar (events) Kafka üzerinden taşınıyor ve sıralı olarak depolanıyor. Ancak, veri analizi, müşteri davranışlarıyla ilgili çıkarımlar yapma veya öneriler oluşturma işlemi Kafka tarafından değil, Kafka’dan veriyi çeken sistemler tarafından gerçekleştirilir.
Kafka’nın Rolü:
- Kullanıcı hareketlerini toplamak (Producers – Veri Üreticileri)
- Bu verileri depolamak ve sıraya almak (Kafka Topics ve Partitions)
- Gerçek zamanlı tüketicilere göndermek (Consumers – Veri Tüketicileri)
Kafka’nın sistemi nasıl yönettiğini adım adım inceleyelim:
- Veri Üreticileri (Producers) – Kullanıcı Hareketlerini Kafka’ya Göndermek
Kimler Producer olabilir?
- Web sitesi tıklamaları (Hangi ürünleri görüntülüyor?)
- Sipariş işlemleri (Müşteri satın alma işlemi yaptı mı?)
- Arama motoru sorguları (Hangi kelimelerle ürün arıyor?)
- Kullanıcı girişleri (Kim, ne zaman giriş yaptı?)
Örnek:
Bir müşteri web sitesine girdi ve bir ürünü sepete ekledi.
- Kafka – Verileri Saklamak ve İşlemek (Kafka Topics & Partitions)
Kafka bu verileri aldığı gibi doğrudan belirli topic’lere yönlendirir ve sıralı bir şekilde depolar. Ancak, veriyi işleyen Kafka değil, Kafka’dan veriyi çeken tüketici sistemlerdir.
Kafka’da Topic Mantığı:
Topic = Bir olay türüne ait tüm verilerin saklandığı yer
Partition = Aynı topic içindeki verilerin bölünerek saklandığı ve tüketicilerin paralel olarak okuyabildiği bölümler.
Kafka’nın buradaki avantajı:
- Verileri sıralı ve tutarlı bir şekilde saklar
- Büyük ölçekli veri akışlarını yönetmek için verileri bölümlere (partition) ayırır ve tüketicilerin paralel olarak okumasını sağlar.
- Verileri kaybetmeden tutabilir ve tüketicilere iletebilir
- Kafka Tüketicileri (Consumers) – Veriyi Kullanmak ve İşlemek
Kimler Consumer olabilir?
- Gerçek zamanlı analiz yapan bir sistem (Big Data, Elasticsearch, AI Modelleri)
- Öneri sistemleri (Amazon’un “Sana özel öneriler” sunması)
- Reklam hedefleme sistemleri (Hangi müşteriye hangi reklamı göstereceğini belirleyen AI modelleri)
- Veri tabanına veri kaydeden servisler (Sipariş geçmişini saklayan bir veritabanı)
Örnek:
Kafka’dan gelen “add_to_cart” verisi bir tüketiciye ulaşıyor:
Elasticsearch: Hangi ürünler daha fazla sepete ekleniyor?
Reklam algoritmaları: Kullanıcıya benzer ürünleri öner.
E-posta sistemi: Müşteriye “Sepetinde ürün unuttun!” e-postası gönder.
Kafka, verileri belirli topic’lerde depolar ve tüketiciler Kafka’dan verileri aktif olarak çeker (pull mekanizması). Kafka, tüketicilere veri göndermez (push yapmaz); tüketiciler Kafka’dan verileri istemli bir şekilde çeker ve işler. Tüketiciler, belirlenen bir offset’ten başlayarak mesajları sırasıyla okur ve kendi tüketim hızlarına göre Kafka’dan veri alırlar.
Bu sistem için Kafka’nın sağladığı avantajlar neler?
- Gerçek zamanlı veri işleme: Kafka, verilerin düşük gecikme ile taşınmasını sağlar ve tüketici sistemler tarafından anlık olarak analiz edilmesine olanak tanır.
- Büyük ölçekli veri yönetimi: Büyük ölçekli veri akışı yönetimi: Kafka, milyonlarca kullanıcıdan gelen veriyi aynı anda alabilir, depolayabilir ve tüketicilere iletebilir.
- Esneklik ve dayanıklılık: Kafka, sistemde bir kesinti olsa bile veriyi kaybetmez.
- Paralel veri işleme: Kafka, verileri birden fazla tüketicinin aynı anda okumasına olanak tanır.
Kafka bu sistemde tam olarak ne yapmış oldu?
- Kafka, verileri üreten sistemler (web sitesi, ödeme sistemi, arama motoru) ile bu veriyi analiz eden veya işleyen tüketici sistemler (veritabanı, analitik sistem, öneri motoru) arasında bir köprü görevi görür
- Kafka, gerçek zamanlı veri akışı sağlar ve sistemler arasında asenkron veri iletimini yönetir.
- Kafka, paralel veri tüketimi ve ölçeklenebilir veri akışı sağlar.
- Kafka, kesintisiz ve güvenilir bir mesaj kuyruğu mekanizmasıyla verileri sıralı bir şekilde depolar ve tüketicilere iletir.
RabbitMQ ve Apache Pulsar gibi sistemler de veri akışını yönetebilir, ancak Kafka’nın temel farkı, büyük ölçekli ve yüksek hacimli olay bazlı veri akışlarını yönetmek için tasarlanmış olmasıdır. Kafka, olay bazlı veri akışı için optimize edilmiş bir altyapı sunar. Verileri kaybetmeden uzun süre saklayabilir ve yüksek hacimli veri akışlarını düşük gecikme ile iletebilir.
Bu yazıyla birlikte, Kafka’nın gerçek zamanlı veri akışını nasıl yönettiğini ve neden kritik bir bileşen olduğunu daha iyi anladığımızı düşünüyorum. Ancak, teoriyle yetinmek olmaz! Bir sonraki makalemde, Kafka’yı adım adım kurarak, nasıl veri taşıdığını ve gerçek bir sistemde nasıl çalıştığını deneyimleyeceğiz.
Sarav Asiye Yiğit – 7 Şubat 2025