
OpenShift Virtualization Platform Mimari Önerileri Serisi – 2
Merhabalar,
Sizlere söz verdiğim gibi OpenShift Virtualization Platform Mimari Önerileri Serimize devam ediyoruz. Ama önce serimizin ilk yazısında neler vardı Onlara bir bakalım?
OpenShift Virtualization, OpenShift’in üzerinde sanal makineleri yerel (native) olarak çalıştıran entegre bir platformdur. Bu platformun başarılı bir şekilde hayata geçirilmesi sadece Kubernetes ve OpenShift’in temel bileşenlerini bilmekle değil, aynı zamanda altyapı, ağ, depolama, güvenlik ve operasyonel süreçlerin doğru tasarlanmasıyla da çok yakından ilgilidir.
Birinci makalede temel olarak şunlara odaklandık:
Küme (Cluster) Boyutlandırma ve Node Rolleri: Yönetim (control plane), iş yükü (worker) sistemleri, sanal makine konfigürasyonlarının seçimi.
Depolama mimarisi: Sanal makineler için performans gereksinimlerini karşılayacak StorageClass’lar, PVC/StoragePolicy’ler ve performansa göre katmanlar (tier).
Network stratejileri: Multus, SR-IOV gibi eklentilerin nerede ve ne zaman kullanılacağı ile network plugin seçim kriterleri.
Güvenlik ve erişim kontrolleri: RBAC, sertifika yapısı, izolasyon ve ağ politikaları gibi güvenlik katmanlarının önemi.
Özetle ilk yazıda, OpenShift Virtualization’a başlarken neden mimari bir bakış gerektiğini ve bu bakışla nelerin doğru planlanması gerektiğini vurgu yaptık. Yani “kurulum nasıl olur”dan ziyade, sürdürülebilir, güvenli ve performanslı bir mimari nasıl kurulur sorusuna cevap aradık.
Bu ikinci serimize ihtiyaç duyduğumuz dış ağları (network) detaylı konuşarak başlayacağız. Bare metal üzerinde kurulan OpenShift Virtualization ortamları, bulut platformlarından farklı olarak bazı kritik altyapı servislerine doğrudan bağımlı şekilde çalışır. Bulut dünyasında DNS, kimlik doğrulama veya yük dengeleme gibi birçok servis altyapı sağlayıcısı tarafından arka planda yönetilirken, OpenShift Virtualization için bare metal ortamlarda bu bileşenlerin tamamı mimarinin bir parçası olarak bilinçli şekilde tasarlanmalıdır. Bu servisler OpenShift’in dışında konumlanır ancak cluster’ın tüm yaşam döngüsü boyunca kararlı ve güvenli çalışabilmesi için vazgeçilmezdir. Doğru planlanmadıklarında performans sorunları, erişim kesintileri ve yönetim zorlukları kaçınılmaz hale gelir.
Bu temel servislerin başında DNS gelir. OpenShift, hem kendi kontrol düzlemi (control plane) bileşenlerine erişimde hem de uygulamaların dış dünyaya açılmasında DNS altyapısına yoğun şekilde bağımlıdır. API servisleri, ingress adresleri ve uygulama yönlendirmeleri isim çözümleme üzerinden çalışır. Küme (Cluster) içindeki servis keşfi OpenShift tarafından sağlansa da, dış erişim tamamen harici DNS altyapısına dayanır. Bu nedenle DNS servislerinin yedekli olması, tüm node’lar tarafından kesintisiz erişilebilir şekilde yapılandırılması ve ileri–ters (forward – reverse) kayıtların doğru çalışması mimarinin temel yapı taşlarından biridir. DNS tarafında yaşanacak bir kesinti, OpenShift ortamının fiilen kullanılamaz hale gelmesine neden olabilir.
Node’ların (kümeyi oluşturan makineler) kurulumu ve yaşam döngüsü açısından DHCP önemli bir rol üstlenir. Bare metal OpenShift kurulumlarında sıklıkla kullanılan PXE tabanlı otomatik kurulum süreçleri ve RHCOS dağıtımları DHCP altyapısı üzerinden ilerler. DHCP yalnızca IP adresi atamakla kalmaz, kurulum sırasında gerekli boot dosyalarını sağlayarak süreci ölçeklenebilir ve hatasız hale getirir. Ancak özellikle kontrol düzlemi node’larının IP adreslerinin değişmemesi kritik önemdedir. Beklenmeyen IP değişimleri etcd bütünlüğünü bozarak kümenin (cluster) yönetilemez hale gelmesine yol açabilir. Bu yüzden DHCP rezervasyonları veya statik IP yapılandırmaları mimari olarak mutlaka tercih edilmelidir.
Zaman senkronizasyonu da OpenShift platformunun sağlıklı çalışması için hayati öneme sahiptir. etcd veri tabanı, API servisleri ve sertifika altyapısı sistem saatlerinin tutarlı olmasına doğrudan bağlıdır. Node’lar arasında zaman farkları oluştuğunda sertifika hataları, senkronizasyon problemleri ve log tutarsızlıkları meydana gelir. Bu durum hem güvenliği zedeler hem de operasyonel sorunların teşhisini zorlaştırır. Bu nedenle OpenShift ortamlarında birden fazla yedekli NTP kaynağı tanımlanmalı ve tüm node’ların merkezi olarak aynı zaman referansını kullanması sağlanmalıdır.
Trafiğin doğru şekilde yönlendirilmesi için OpenShift hem dahili hem de harici yük dengeleme (load balancer) mimarilerini destekler. Dahili yük dengeleme yaklaşımı, keepalived tarafından yönetilen sanal IP adresleri üzerinden çalışır ve hızlı kurulum gereken senaryolarda pratik bir çözüm sunar. Küçük ve orta ölçekli ortamlar için yeterli olurken, yoğun uygulama trafiği olan sistemlerde sınırlı kalabilir. Bu gibi durumlarda harici yük dengeleme çözümleri çok daha sağlam bir mimari sağlar. Donanımsal yük dengeleme cihazları veya HAProxy , NGINX gibi yazılımsal çözümler, gelişmiş sağlık kontrolleri, yük dağılımı ve kesintisiz erişim açısından önemli avantajlar sunar. OpenShift’in esnek yapısı sayesinde zaman içinde dahili yük dengeleyiciden harici mimariye geçiş yapmak da mümkündür.
Kurumsal ortamlarda bir diğer kritik konu kimlik doğrulama servisleridir. OpenShift’in dahili kullanıcı yönetimi küçük ortamlar için yeterli olsa da, büyük ölçekli sistemlerde parola politikaları, erişim yönetimi ve güvenlik gereksinimleri açısından yetersiz kalır. Bu nedenle Active Directory, Red Hat Identity Management veya OAuth/OIDC tabanlı kurumsal kimlik sistemleriyle entegrasyon önerilir. Böylece kullanıcı yönetimi merkezi hale gelir ve güvenlik standartları korunur. Ayrıca bu servislerin erişilemez olduğu durumlara karşı, küme (cluster) yöneticileri için sertifika tabanlı erişim mekanizmalarının yedek çözüm olarak yapılandırılması kritik bir güvenlik önlemidir.
OpenShift ortamlarının sürekliliği açısından konteyner kayıt deposu (container registry) altyapısı da önemli bir bileşendir. Küme (Cluster) kurulumu, güncellemeler ve OpenShift Virtualization gibi özelliklerin çalışabilmesi için sürekli olarak container imajlarına ihtiyaç duyulur. Varsayılan olarak bu imajlar Red Hat tarafından yönetilen internet üzerindeki kayıt deposu (registry) servislerinden çekilir. Ancak bant genişliği kısıtlı ortamlarda, çoklu küme (cluster) senaryolarında veya izole ağ yapılarında bu yaklaşım performans ve erişilebilirlik sorunlarına yol açabilir. Bu nedenle kurum içinde konumlandırılmış bir konteyner kayıt deposu kopyası kullanmak hem performansı artırır hem de dış bağımlılığı azaltır.
Red Hat abonelikleri ile birlikte sunulan yerel Quay tabanlı mirror kayıt deposu çözümü, OpenShift içeriklerinin kurum içinde barındırılmasına olanak tanır. Bu sayede güncellemeler daha kontrollü yapılır, ağ trafiği optimize edilir ve kesintili bağlantı senaryolarında dahi sistem çalışmaya devam edebilir. Bununla birlikte OpenShift, kurumların mevcut konteyner kayıt depo altyapılarını da kullanabilecek esnek entegrasyon seçeneklerini destekler.
Şimdi ise, kümeyi (cluster) oluşturan fiziksel sunucularla ilgili biraz daha detaya girelim.
Donanım gereksinimleriyle ilgili detaylı bilgiler için ürün dokümantasyonu referans alınmalıdır.
https://access.redhat.com/articles/6907891
https://access.redhat.com/articles/7128992
OpenShift, donanım desteğini kullandığı Red Hat Enterprise Linux (RHEL) sürümünden devralır. Kümede kullanılan RHCOS’un hangi RHEL sürümüne dayandığı ilgili teknik makalede, https://access.redhat.com/articles/6907891 belirtilmektedir.
Ürün dokümanlarında belirtilen minimum gereksinimlerin ötesinde, OpenShift Virtualization için katı donanım kuralları yoktur. Donanım ihtiyacı, hedeflenen performans, kapasite, yoğunluk ve dayanıklılık seviyelerine göre şekillenir.
Kapasite planlaması tamamen ortamınıza ve iş yüklerinize bağlıdır. CPU ve bellek kaynakları her fiziksel sunucunun taşıyabileceği toplam yükü doğrudan etkiler. Kaynakların aşırı tahsisi (oversubscription), donanımın daha verimli kullanılmasını sağlar ancak aynı anda çok sayıda sanal makine yoğun kaynak talep ederse performans problemleri oluşabilir. Farklı uygulamalar CPU ve bellekten farklı oranlarda faydalanır. Eğer iş yüklerinizden biri ağırlıklıysa, donanımı dengeli oranlarla tasarlamak faydalıdır. Örneğin her 1 CPU çekirdeği için 8 GB bellek gibi bir yapı, kaynak israfını önleyebilir. https://access.redhat.com/articles/7107457 dokümanı çok faydalı bir doküman. Bu doküman sayesinde aşağıda olanlara karar verebilirsiniz.
- İş yükü için gerekli ham kapasitenin belirlenmesi,
- Gerekli kapasiteye aşırı tahsis (overcommitment) oranının dahil edilmesi,
- Fiziksel sunucu boyutunun belirlenmesi ve bunun küme üzerindeki etkisinin değerlendirilmesi,
- Küme mimarisine göre fiziksel sunucu sayısının ayarlanması,
- Yüksek erişilebilirlik (High Availability) gereksinimlerini karşılamak için kapasitenin ek olarak planlanması,
- Özel kaynaklara (GPU, yüksek hızlı disk, özel ağ vb.) ilişkin değerlendirmelerin yapılması.
Bir OpenShift kümesindeki fiziksel sunucuların birebir aynı donanımda olması zorunlu değildir. Farklı marka, model ve kapasitede sistemler birlikte çalışabilir. Ancak donanımdaki her farklılık:
- Yönetim karmaşıklığını artırır,
- Konfigürasyon yükünü büyütür,
- Canlı taşıma (live migration) ve kaynak planlamasını zorlaştırabilir.
Bu nedenle mümkün olduğunca aynı donanıma sahip fiziksel sunucular tercih edilmelidir. Donanımlar genellikle parti parti yenilendiği için homojen gruplar oluşturmak en doğru yaklaşımdır. Bunun avantajları:
- Aynı fiziksel yapıya sahip node’lara aynı konfigürasyonlar kolayca uygulanır,
- CPU nesilleri farklıysa VM’ler düşük ortak özellik seviyesine zorlanmaz,
- Performans farklarından kaynaklı sürpriz sorunlar azaltılır.
Bu gruplama tek küme içinde label, selector ve affinity kurallarıyla yapılabilir. Ayrı küme kurmaya gerek yoktur.
Her fiziksel sunucu üzerinde kubelet, container runtime ve sistem servisleri için belirli CPU ve bellek ayrılması önerilir. Bu, node stabilitesini korumak için kritik önemdedir.
Manuel hesaplama karmaşık olabileceğinden otomatik kaynak rezervasyonu önerilir: autoSizingReserved: true.
Bu ayar sayesinde sistem, node kapasitesine göre gerekli kaynakları otomatik ayırır.
Varsayılan olarak OpenShift tek bir ağ arayüzü üzerinden: Node-to-node trafiği, Pod trafiği, Storage erişimi, Control plane iletişimini yürütür. Ancak sanallaştırma ortamlarında yüksel hızlı olsa bile tek NIC kullanımı önerilmez. Tek kart, dayanıklılık sağlamaz, NIC, kablo veya switch arızasında tüm trafiği keser.
Önerilen yapı, birden fazla NIC kullanılarak bonding (özellikle LACP – mode 4) yapılandırılmasıdır. Bu sayede, yedeklilik sağlanır, toplam bant genişliğini artırır, trafik türlerine göre ayrıştırma (opsiyonel ama ideal) sağlanır.
Genelde şu yapı kullanılır:
SDN + control plane trafiği -> 1. bond
Storage -> 2. bond
Backup -> 3. bond
Replication -> 4. bond
Live migration -> 5. bond
VM uygulama trafiği -> 6. bond
Bu sayede gecikme azalır, performans sabitlenir, çakışmalar önlenir.
NMState, OpenShift’te host seviyesinde ağ yapılandırmasını merkezi ve deklaratif olarak yönetir.
Bond, VLAN, bridge ve routing yapılarını tek konfigürasyon dosyasında tanımlayarak, hataları azaltır, güncellemeleri atomik yapar, kesinti riskini düşürür. Özellikle yüksek erişilebilirlik gerektiren ortamlarda kesinlikle önerilir.
Fiziksel sunucu diskleri yalnızca işletim sistemi için değil, aynı zamanda, konteyner imajları, loglar, etcd verileri, kubelet verileri için kullanılır. Bu nedenle SSD veya NVMe zorunlu denecek kadar önemlidir. Kontrol düzlemi için mutlaka flash disk önerilir. RAID ile dayanıklılık artırılabilir. Minimum öneri en az 250 GB’tır. OpenShift Virtualization yalnızca RHCOS fiziksel sunucular üzerinde çalışır.
RHEL node’lar OpenShift için kullanılabilir ancak sanallaştırma için uyumlu değildir.
RHCOS, konteyner odaklıdır, CRI-O ile entegredir, rpm-ostree ile merkezi olarak yönetilir, sürücü veya ek paket gerekiyorsa image layering yöntemi kullanılır.
Node Başına Pod Limiti, varsayılan maksimum, 250 Pod / node
Bu sayıya, uygulama pod’ları, sistem Servisleri, VM’ler dahildir Platform servisleri genelde 40–60 pod tüketir. OVN-Kubernetes kullanıldığında IP bloğu büyütülerek, 500 pod, hatta 1000+ pod mümkün olabilir. Ancak, çok yüksek yoğunluk operasyonel risk yaratır, VM’ler genelde kaynak sınırına daha erken ulaşır. Pratikte, 500 pod makuldür. 350–400 VM üzeri ciddi planlama gerektirir
Özellikle VM ve konteyner birlikte çalışıyorsa daha dikkatli olunmalıdır.
OpenShift Virtualization’da sanal makine diskleri, Kubernetes’in yerleşik depolama yaklaşımıyla uyumlu şekilde Persistent Volume Claim (PVC) nesneleri üzerinden yönetilir. Pratikte bu, her bir VM diskinin ayrı bir PVC ile temsil edildiği anlamına gelir. Bu PVC’ler, ihtiyaç oluştuğunda (on-demand) arka planda CSI (Container Storage Interface) sürücüsü tarafından sağlanan depolama üzerinde “provision” edilir. CSI sürücüsü genellikle ilgili storage üreticisi tarafından sağlanır ve OpenShift’in, vendor’a özel depolama sistemleriyle standart bir yöntemle konuşmasını sağlar.
CSI’nin temel katkısı, depolama tarafındaki işlemleri OpenShift açısından soyutlamasıdır. Yani OpenShift tarafında “disk oluştur”, “bağla”, “büyüt”, “snapshot al” gibi operasyonlar standart API’ler üzerinden istenir. CSI sürücüsü de bu talepleri storage sisteminin anlayacağı şekilde gerçekleştirir. Bu süreçte sürücü, arka uç depolama üzerinde uygun bir mantıksal volume/kaynak oluşturulmasını ve bu kaynağın VM’i çalıştıran node’a bağlanıp kullanılabilir hale gelmesini koordine eder.
Bu yaklaşım, geleneksel sanallaştırma platformlarındaki yaygın modelden belirgin şekilde ayrışır. Klasik yapılarda çoğu zaman tek bir datastore mantığıyla, örneğin bir iSCSI/FC LUN veya bir NFS export gibi ortak bir depolama alanı oluşturulur ve çok sayıda sanal makinenin diskleri bu ortak alanın içinde tutulur. OpenShift Virtualization’da ise her VM diskinin ayrı bir PVC (dolayısıyla ayrı bir “yönetilen depolama kaynağı”) olarak ele alınması, disk bazında daha ince seviyede yönetimi mümkün kılar. Burada “ayrı kaynak” ifadesi fiziksel olarak ayrı disk anlamına gelmez, çoğu durumda bu mantıksal kaynaklar aynı fiziksel disk havuzlarını paylaşır, ancak yönetim ve politika uygulama katmanı disk/PVC seviyesinde yapılır.
Her diskin bağımsız bir kaynak gibi yönetilebilmesi, depolama üreticilerinin yeteneklerini VM diskleri özelinde sunabilmesine de kapı aralar. Örneğin bazı CSI sürücüleri, PVC seviyesinde QoS, snapshot veya clone gibi özellikleri destekleyebilir. Bu sayede kritik bir VM’in diskine farklı performans/koruma politikası uygulanabilirken, daha az kritik iş yükleri farklı bir politika ile yönetilebilir. Hangi özelliklerin kullanılabileceği ise storage platformunun ve ilgili CSI sürücüsünün desteklediği kabiliyetlere bağlıdır.
Canlı taşıma (live migration) senaryosunda, depolama tarafında ek bir gereksinim ortaya çıkar. Bir VM canlı taşınırken, VM’in disklerinin aynı anda hem kaynak node’da hem de hedef node’da erişilebilir olması gerekir. Bu nedenle, taşınacak VM’e ait disklerin ReadWriteMany (RWX) erişim modunu sağlayan PVC’ler üzerinde bulunması beklenir. RWX, aynı volume’un birden fazla node tarafından eşzamanlı bağlanabilmesini ifade eder. Teorik olarak hem dosya tabanlı (ör. NFS) hem de bazı blok tabanlı çözümler RWX senaryolarını destekleyebilir, ancak pratikte RWX’in nasıl sağlandığı, ek gereksinimler veya kısıtlar (performans, locking davranışı, desteklenen volume tipi vb.) storage üreticisine göre değişebilir. Bu yüzden canlı taşıma hedefleniyorsa, kullanılacak storage platformu ve CSI sürücüsüyle RWX gereksiniminin uyumluluğu mutlaka doğrulanmalıdır.
Özetle, OpenShift Virtualization’daki CSI Mimarisi, volume oluşturma ve yönetme, node’a bağlama (mount/attach), snapshot alma ve volume büyütme gibi işlemleri depolama sistemi seviyesinde koordine eder. Bu sayede sanal makine diskleri Kubernetes-native bir modelle yönetilirken, depolama tarafındaki gelişmiş yetenekler (varsa) daha kontrollü ve disk/PVC seviyesinde uygulanabilir hale gelir.
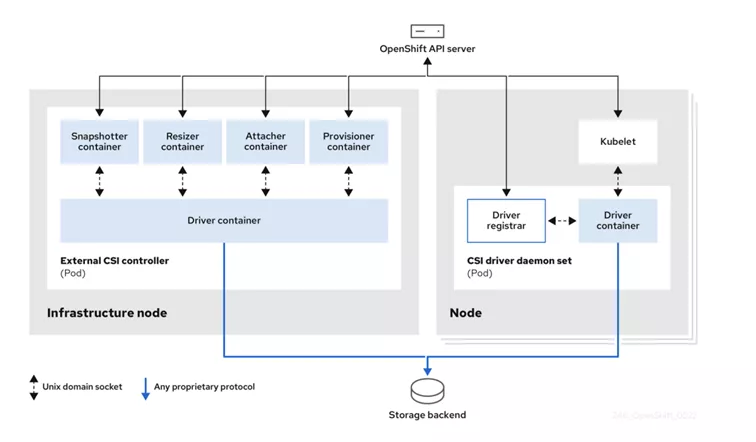
OpenShift ortamında bir depolama sisteminin sanal makineler ve container iş yükleri tarafından kullanılabilmesi için ilk adım, ilgili CSI (Container Storage Interface) sürücüsünün bir Operator aracılığıyla cluster’a kurulmasıdır. CSI Operator doğrudan OpenShift üzerine deploy edilir ve temel görevi storage entegrasyonunu sağlayan tüm CSI bileşenlerini otomatik olarak oluşturmak, konfigüre etmek, güncellemek ve sağlığını izlemektir. Operator’un kendisi doğrudan storage üzerinde işlem yapmaz; asıl iş yükünü yönettiği CSI pod’ları gerçekleştirir. Bu yönüyle Operator, depolama entegrasyonunun yaşam döngüsünü yöneten bir kontrol katmanı olarak düşünülebilir.
Operator kurulduktan sonra, CSI mimarisi iki ana çalışma alanına ayrılır, merkezi kontrol bileşenleri ve node seviyesindeki çalışma bileşenleri. Merkezi kontrol katmanı, diyagramda sol tarafta gösterilen External CSI Controller bölümüdür ve çoğu mimaride infrastructure node’lar üzerinde çalıştırılır. Bu bölümde yer alan provisioner, attacher, resizer ve snapshoter gibi bileşenler; yeni volume oluşturma, mevcut volume’ları node’lara bağlama, kapasite büyütme ve snapshot alma gibi tüm yönetimsel işlemleri koordine eder. Bu bileşenlerin her biri, storage sistemiyle doğrudan konuşmak yerine CSI driver container üzerinden standart bir arayüzle iletişim kurar. CSI driver ise bu talepleri storage sisteminin kendi API’lerine veya protokollerine dönüştürerek arka uç depolama üzerinde gerekli işlemleri gerçekleştirir.
Diyagramın sağ tarafında yer alan CSI driver daemon set ise node seviyesindeki operasyonlardan sorumludur ve OpenShift cluster’daki her worker node üzerinde otomatik olarak çalışır. Bu katmanda bulunan driver container ve driver registrar bileşenleri, CSI sürücüsünü kubelet’e tanıtır ve storage üzerinde oluşturulmuş volume’ların ilgili node’a mount edilmesini sağlar. Kubelet, bu mount edilen depolama kaynağını sanal makineye veya container iş yüküne disk olarak sunan bileşendir. Böylece merkezi olarak oluşturulan bir volume, fiziksel olarak VM’nin çalıştığı node üzerinde erişilebilir hale gelir.
Tüm bu süreç, OpenShift API Server üzerinden tetiklenir. Bir kullanıcı PVC oluşturduğunda ya da bir sanal makine yeni bir disk talep ettiğinde istek önce API Server’a ulaşır. API Server bu isteği CSI controller bileşenlerine yönlendirir; controller tarafı storage üzerinde gerekli mantıksal volume’u oluşturur ve bağlantı bilgilerini hazırlar. Ardından node tarafındaki CSI bileşenleri devreye girerek bu volume’u ilgili node’a bağlar ve VM’nin kullanabileceği hale getirir. Snapshot alma, disk büyütme veya klonlama gibi işlemler de aynı akışın farklı bileşenleri üzerinden yürütülür.
Bu mimarinin önemli bir avantajı, OpenShift cluster’ında birden fazla CSI sürücüsünün aynı anda çalışabilmesidir. Böylece farklı üreticilere ait storage sistemleri aynı ortamda birlikte kullanılabilir; sanal makineler ihtiyaçlarına göre farklı disk tipleri, performans seviyeleri ve erişim modları seçebilir. Gelişmiş özelliklerin — örneğin snapshot, QoS, clone veya replikasyon gibi yeteneklerin — sunulup sunulamayacağı ise tamamen kullanılan storage platformunun ve ilgili CSI sürücüsünün kabiliyetlerine bağlıdır.
Özetle, CSI Operator OpenShift’e kurularak depolama entegrasyonunun yönetimini üstlenir; controller bileşenleri genellikle infrastructure node’larda merkezi depolama operasyonlarını yürütür; daemon set olarak çalışan node bileşenleri ise disklerin fiziksel olarak sanal makinelere bağlanmasını sağlar. Diyagramın gösterdiği bu ayrışmış ama koordineli yapı sayesinde OpenShift Virtualization, modern, ölçeklenebilir ve üretici bağımsız bir depolama mimarisi üzerinde sanal makineleri güvenli ve esnek biçimde çalıştırabilir.
OpenShift mimarisi, aynı cluster içerisinde birden fazla CSI sürücüsünün birlikte çalışmasına izin verecek şekilde tasarlanmıştır. Bu sayede farklı üreticilere ait depolama sistemleri tek bir OpenShift ortamına entegre edilebilir ve sanal makineler ihtiyaçlarına göre farklı disk tipleri, erişim protokolleri ve kullanım modları üzerinden çalıştırılabilir. Bir VM için yüksek performanslı blok depolama tercih edilirken, başka bir VM için paylaşımlı dosya tabanlı bir storage kullanılabilir. Bu esneklik, kurumların tek bir üreticiye bağımlı kalmadan kendi iş yüklerine en uygun depolama çözümlerini seçebilmesini sağlar.
CSI mimarisinin sunduğu bu standart katman, gelişmiş depolama özelliklerinin OpenShift ortamına taşınmasını da mümkün kılar. Ancak bu noktada sunulabilecek yetenekler doğrudan storage üreticisinin platformuna ve ilgili CSI sürücüsünün implementasyonuna bağlıdır. Örneğin bazı storage sistemleri, bir PVC’nin kopyasını compute node üzerinden veri okuyup yazmadan doğrudan storage altyapısı içinde oluşturabilir. Bu “storage üzerinde clone” yaklaşımı, özellikle golden image veya template üzerinden çok sayıda sanal makine oluşturulurken ciddi zaman kazancı sağlar ve cluster üzerindeki gereksiz I/O yükünü ortadan kaldırır.
Benzer şekilde, birçok CSI sürücüsü sanal makine diskleri için snapshot alma yeteneği sunabilir. Snapshot’lar, bir diskin belirli bir andaki durumunu saklayarak işletim sistemi güncellemeleri, uygulama değişiklikleri veya test çalışmaları öncesinde hızlı geri dönüş noktaları oluşturulmasını sağlar. Ayrıca modern yedekleme çözümlerinin önemli bir kısmı snapshot tabanlı çalıştığı için, bu yetenek veri koruma stratejilerinin temelini oluşturur. Ancak snapshot fonksiyonunun kullanılabilirliği tamamen storage platformunun ve CSI sürücüsünün bu özelliği desteklemesine bağlıdır.
Bazı depolama sistemleri CSI üzerinden kapasite takibi ve kota yönetimi de sunabilir. Bu sayede her bir PVC’nin ne kadar alan kullandığı merkezi olarak izlenebilir ve belirli projeler veya iş yükleri için depolama sınırları tanımlanabilir. Bu yaklaşım, büyük ölçekli ortamlarda kapasitenin kontrolsüz şekilde tükenmesini engelleyen önemli bir yönetişim mekanizması oluşturur.
Performans tarafında ise bazı CSI sürücüleri disk seviyesinde kalite servisleri (QoS) sunarak IOPS limitleri, bant genişliği garantileri veya gecikme hedefleri tanımlanmasına olanak tanır. Bu özellikler özellikle farklı öneme sahip iş yüklerinin aynı fiziksel disk havuzunu paylaştığı ortamlarda kritik rol oynar. Performans açısından hassas sanal makineler korunurken, daha düşük önemdeki sistemlerin kaynak tüketimi kontrol altında tutulabilir.
Yüksek erişilebilirlik gerektiren senaryolarda, özellikle blok tabanlı depolama çözümleri için multipath I/O desteği de CSI üzerinden sağlanabilir. Bu yapı, node ile storage sistemi arasında birden fazla veri yolunun aktif olarak kullanılmasını mümkün kılar. Herhangi bir yolun kesintiye uğraması durumunda erişim devam ederken, aynı zamanda paralel yollar performans artışı da sağlayabilir. Bu yapılandırmanın oluşturulması ve yönetilmesi CSI sürücüsü tarafından otomatik şekilde gerçekleştirilir.
Bunun dışında replikasyon, veri sıkıştırma ve deduplikasyon gibi birçok gelişmiş depolama özelliği çoğu zaman OpenShift açısından şeffaf şekilde storage altyapısı üzerinde çalışır. Bazı üreticiler bu yetenekleri PVC seviyesinde yapılandırılabilir hale getirirken, bazıları bu işlemleri tamamen storage sisteminin iç mekanizması olarak sunar. Hangi yaklaşımın mevcut olduğu yine vendor’a ve kullanılan protokole bağlıdır.
Tüm bu özelliklerin kullanılabilirliği her storage platformunda aynı değildir. Bazı yetenekler yalnızca belirli erişim protokollerinde (örneğin NFS veya iSCSI) ya da belirli volume tiplerinde (blok veya dosya tabanlı) desteklenebilir. Ayrıca bu özelliklerin kapasite kullanımı ve performans üzerindeki etkileri de storage üreticisine göre değişiklik gösterir. Bu nedenle OpenShift Virtualization mimarisi tasarlanırken, yalnızca CSI entegrasyonunun varlığına bakmak yeterli değildir; hangi özelliklerin hangi koşullarda desteklendiğinin storage sağlayıcısı ile detaylı şekilde doğrulanması kritik önem taşır.
Sonuç olarak OpenShift Virtualization, yalnızca sanal makineleri OpenShift üzerinde çalıştıran bir özellik değildir. Doğru planlandığında altyapı, ağ, depolama ve operasyon süreçlerini bütüncül şekilde dönüştüren modern bir platform yaklaşımıdır. Bare metal ortamlarda DNS, DHCP, NTP ve yük dengeleme gibi dış servislerin bilinçli tasarımı, donanım standardizasyonu ve kapasite planlamasının gerçekçi yapılması, çoklu NIC ve doğru network ayrıştırmasının uygulanması, CSI tabanlı depolama mimarisinin yetenek ve sınırlarının net anlaşılması bu dönüşümün temel taşlarını oluşturur. Mimari kararlar yalnızca “çalışır mı?” sorusuna değil, “ölçeklenir mi, sürdürülebilir mi, geri döndürülebilir mi ve güvenli mi?” sorularına da cevap vermelidir. OpenShift Virtualization’ı başarılı kılan unsur, kurulum adımlarından ziyade bu bütüncül mimari bakış açısıdır. Doğru tasarlanmış bir yapı, esneklik, performans ve üretici bağımsızlığı sağlarken, gelecekteki büyüme ve değişim senaryolarına da hazır bir altyapı sunar. OpenShift Virtualization Platform Mimari Önerileri Serisi’nin ikinci bölümünü de bu şekilde tamamladım. Serinin yeni bölümünde görüşmek üzere.
Sarav Asiye Yiğit * 18 Şubat 2026
Kaynakça:
https://access.redhat.com/sites/default/files/attachments/openshift_virtualization_architecture_guide_v1.0.0.pdf