Merhaba;
Bugün sizlere Oracle’ın büyük veri (“big data”) için konumlandırdığı çözümlerinden bahsetmek istiyorum.
Öncelikle kısaca büyük veri nedir sorusunu cevaplamaya çalışalım. Büyük veri, pek çok kaynaktan gelen, pek büyük (muazzam, hacimli) yapısal olmayan veri olarak tanımlanıyor. Bu kaynaklar neler acaba? Sosyal ağlar, banka ve finans servisleri, e-ticaret servisleri, web-merkezli servisler, internet search indeksleri, bilimsel araştırmalar, döküman araştırmaları (“searches”), medical kayıtlar, web logları bu kaynaklara örnek olarak verilebilir. Aşağıdaki görselden göreceğimiz gibi, günümüzde pek çok yeni veri kaynaklarıyla karşı karşıyayız.

Bu kadar farklı kaynaktan gelen bu derece hacimli veriyi nasıl yöneteceğiz? Daha önemlisi, bu verilerden yeni iş imkanları nasıl oluşturabileceğiz, mevcut işimizi nasıl büyüteceğiz? Kısaca bu veriyi nasıl kazanca dönüştüreceğiz? Büyük verinin geliştirebileceği hedefler olarak elbette pek çok şey sayabiliriz. Ama sanırım en önemlileri, akıllı verinin keşfedilmesi, e-ticaret davranışının anlaşılması, “sentiment” analizi, destek süreci etkileşimleri olarak sıralanabilir. Büyük verinin karakteristiği 4V ile açıklanıyor: “Volume”, “Velocity”, “Variety”, “Value”.
“Volume” derken artık PetaByte’larca veriden bahsediyoruz. “Velocity” ile verinin çok hızlı bir oranda üretildiği ifade ediliyor. “Variety” ile çok değişik türden veri ile karşı karşıya kaldığımızı ifade etmeye çalışıyoruz. Tarih, karakterler, sayılar, imajlar, bloglar, tweet’ler, dökümanlar ve daha pek çok farklı veri türünü anlamak zorundayız. Asıl önemli olan karakteristik, tüm bu verilerden organizasyon için kazanç sağlayacak değeri ortaya çıkarmaktır. İşte bu karakteristik, “value” olarak ifade ediliyor. Özet olarak aslında yapmamız gereken, büyük veri ile karşımıza çıkan zorlukları, organizasyonlar için pozitif fırsatlara çevirebilmemizdir.
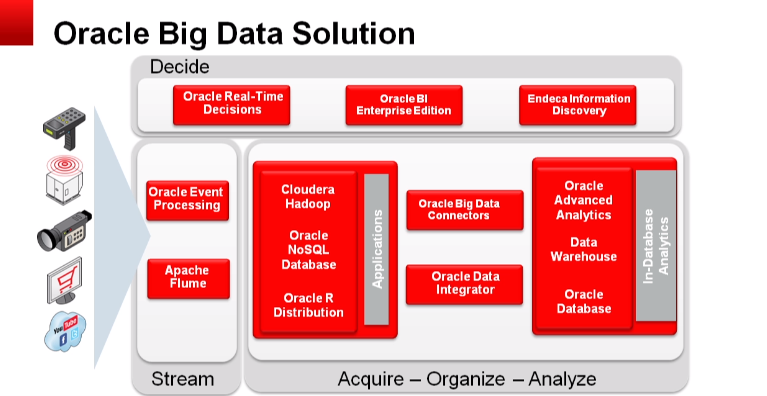
Oracle, büyük veri için dört fazdan oluşan bir çözüm seti sunuyor. Bu dört fazı, “Acquire”, “Organize”, “Analyze”, ve “Decide” olarak isimlendiriyor. “Acquire” fazda veriyi elde etmek zorundayız. “Organize” fazda, veriyi fiziksel bir yere konumlandırmamız gerekiyor. Ne yapabileceğimize bakmak için veriyi fiziksel olarak bir yerde tutmamız gerekiyor. Verinin arkasındaki değeri anlamak için “Analyze” fazında, veri üzerinde analiz yapmamız gerekiyor. “Decide” fazında çıkan analiz sonucuna göre, cevaplamaya çalıştığımız sorular için en iyi kararı vermemiz gerekiyor.


“Acquire” fazında, daha önce dediğimiz gibi pek çok kaynaktan gelen veriyi toplamak zorundayız. Tüm veriyi bir yerlere koymalıyız ki üzerinde çalışabilelim. Bu amaçla verinin özelliklerine bağlı olarak veriyi iki (aslında üç eğer veri tipi ilişkisel veri tabanı formatına uyuyorsa ama ben burda biraz daha yapısal olmayan veya çok çok az yapısal veriyi düşündüğüm için iki dedim) farklı noktada konumlandırabiliriz: “Hadoop Distributed File System (HDFS)” veya “Oracle NoSQL Database”. Veriyi tutacağımız noktayı ihtiyaca göre doğru belirlememiz gerekiyor. HDFS’den bahsettiğimizde, bir doya sistemini ifade diyoruz. Paralel çalışan ve yüksek oranda yazma işlemlerinin yapıldığı bir yapıdır. “Oracle No SQL Database” den bahsettiğimizde, adı üstünde bir veritabanı var karşımızda. Basit bir veri yapısına sahip. Yüksek oranda rastgele (“random”) okuma ve yazma işlemi yapar. Indeks yapısına sahiptir.
Hadoop mimarisine kısaca bakmak gerekirse. Dosyaların saklandığı HDFS yapısından ve programlama yapmamıza olanak sağlayan MapReduce bileşeninden oluşur.

Hadoop mimarisi özellikle, “click stream storage & analysis” için kullanılır. Örnek vermek gerekirse, X dakikadan daha çok süren web oturumlarının sayısı, en fazla/en az görüntülenen web sayfaları gibi. “Sentiment analysis” de Hadoop mimarisinde kullanılan örneklerden birisidir. Belli bir kelimeyi, cümleyi içeren kaç tane yorum var mesela? Aynı şekilde “relationship discovery” analizi içinde Hadoop mimarisi kullanılır. X ve Y bileşenleri kaç kez aynı anda oluşmuş? Hangi bileşenler birbiriyle zamansal veya yakınsal ilişkili olarak belirmiş?
Hadoop yapısının diğer güzelliği, üzerinde dosyaların birden fazla kopyasını tutulabilmesi, dağıtık yapının bir “cluster” üzerinde olması ve ihtiyaç duyulduğunda yeni “node” ların hızlıca yapıya eklenebilmesidir. “stream” lerin depolanması için oldukça elverişlidir.
“Oracle NoSQL Database” de bir opsiyon demiştik verileri tutacağımız nokta olarak. Ama hangi durumlarda? Aslında yine yapısal olmayan veriden bahsediyoruz ama en azından key-value olarak veriyi ayrıştırabiliyorum. Yani HDFS, tamamen yapısal olmayan “raw” veri için çok uygun bir ortam ama veride az da olsa bir yapısallık yakalabiliyorsak NoSQL veri tabanında konumlandırabiliriz. Major-minor key-value veri modeline göre çalışır. Read/insert/update/delete operasyonlarını destekler. RMW (ReadModify Write) desteği vardır. Örneğin aşağıdaki şekilde, “userid” major key ve “userid” ye ait özellikler minor key’dir.

“Acquire” faz için Oracle, Oracle Big Data Appliance ürününü konumlandırıyor. Aşağıda “Oracle Big Data Appliance”ın dizayn ilkelerini görebilirsiniz. Güvenlik, yönetim kolaylığı, performans, ölçeklenebilirlik en önemli dizayn ilkeleri olarak sayılabilir.

“Acquire” fazda veriyi doğru noktada topladığımızı varsayıyorum. Şimdi yapmamız gereken, bu veri üzerinde analitik çalıştırabilmek için veriyi ilişkisel veritabanına alabilmek. İşte bu fazı Oracle, “organize” olarak tanımlıyor. Verinin Hadoop ve/veya NoSQL veritabanından ilişkisel veritabanına alınmasını mümkün kılan farklı türden “Oracle Connector” ler vardır.
Örneğin “sesion log” lardan anlamlı veriyi çıkarmak için adımları belirleyelim. Öncelikle verinin içeriğine göre, veriyi ya HDFS veya NoSQL veritabanına yüklememiz gerekiyor (önemli not olarak belirtmek isterim ki elbette veri zaten geleneksel veritabanına konumlandırılacak yapıdada olabilir. Ama burda yapısal olmayan veya çok çok az yapısal veriden bahsediyorum). Ardından MapReduce ile içeriği safileştiriyoruz. Daha sonra safileştirdiğimiz bu veriyi analiz için veritabanına yüklüyoruz ve analiz sonuçlarına göre karar veriyoruz.
“Oracle Big Data Connector” leri, “Oracle loader for Hadoop (OLH)”, “Oracle SQL Connector for Hadoop Distributed File System (OSCH)”, “Oracle Data Integrator Application Adapter for Hadoop (ODIAAH)” ve “Oracle R Connector for Hadoop (ORCH)” olarak sıralanabilir.

Aşağıdaki şekilde göreceğimiz gibi, “Oracle Big Data Connector” ler sayesinde “Oracle database” ve Hadoop iletişim kurabiliyor.

“Analyze” fazında Oracle, “Oracle R Enterprise”, “Oracle R Connector for Hadoop”, “Oracle Exadata”, “Oracle mining tools” çözümlerini konumlandırıyor. Oracle Exadata için genel özellikleri belirten görseli aşağıda görebilirsiniz.

Oracle’ın sunduğu ileri düzeyde analitik çözümlerini aşağıdaki tablo göstermektedir.

Bu noktada “Oracle’s R Distribution” dan bahsetmek istiyorum. “R engine”, “Oracle R Enterprise” ve “Oracle R Connector for Hadoop” paketlerini içeriyor ve “Oracle Enterprise Linux” ile entegredir. “Oracle R”, Oracle veritabanı ile etkileşimde bulunabilir ve veri değiş tokuşu yapabilir.
“Decide” olarak isimlendirilen 4.fazda Oracle, “Real-Time Decisions”, “Oracle BI Enterprise Edition”, “Oracle Endeca Information Discovery” çözümlerini sunmaktadır. Bu çözümleri “Oracle Exalytics” üzerinde çalıştırabilirsiniz. Özet olarak Aşağıdaki görsellerde, bu 4 faz için önerilen çözümleri, bu çözümler için Oracle’ın sunduğu donanım ve yazılımın birlikte çalıştığı optimize appliance’ları görebilirsiniz.


Daha sonraki yazılarımda çözümlerin biraz daha detayına girmek istiyorum.
25 Şubat 2018 Pazar – Asiye Yiğit