Merhaba;
Sizlere bugün büyük veriyle ilgili kavramları özetlemeye çalışacağım. 1995 yılında sektöre başladığımda, MegaByte boyutunda floppy disklerle çalıştığımı hatırlıyorum dosyaları bir yerden bir yere kopyalarken. Günümüze baktığımızda veri miktarları, Petabyte’lardan artık, Exabyte, Zettabyte, Yottabytle’lara doğru gidiyor.
Elimizde şöyle bir konu olsun. Ürün dağıtıcısı, faturalarla, kendisine gelen ödemeleri karşılaştırarak ödemeyle ilgili risklerini belirlemek istesin. Fatura sistemi ve alınan ödemelere ait yapının Oracle üzerinde tutulduğunu düşünelim. Veriyi sunmak için Tableau yazılımını kullandıklarını varsayalım. Bu çalışmayı, geleneksel yöntemlerle nasıl yapıyoruz?

Şekil 1. Geleneksel yöntem
Şekil 1.’de bu bilgileri tuttuğumuz aktif veri tabanlarındaki verilerden, ETL yöntemleriyle veriyi temizledikten sonra, analitik uyguluyoruz, çıkan veriyi bir veri tabanına yazarak, üst yönetim için veriyi görselleştiriyoruz. Diğer taraftan, 16 TB’lık arşiv veriyi incelememiş durumdayız. Veri bilimcileri, bu noktada şikayet edecektir. Geçmişe dönük veriyi analiz edebilirlerse daha doğru tahminler yapabileceklerini söyleyeceklerdir. Aslında bu çözüme baktığımızda hayli pahalı ve ek olarak yavaş bir sistem. Geleneksel yöntem yerine, büyük verinin bize sunduğu imkanlardan faydalanırsak, ortaya nasıl bir resim çıkacak?

Şekil 2. Büyük veri ortamı
Şekil 2.’de “Big Data analytics system” dediğimiz dağıtık, yedekli ve parallel çalışan bir yapı kurgulayarak, elimizdeki tüm verileri maliyet avantajı da yakalayarak bu sistemin içine alıp, uygun analitikleri çalıştırıp, çıkan sonuçları bir veri tabanına yazarak, üst yönetim için bulgularımızı görselleştirebiliyoruz. Bu işlemi, büyük veri ile çözdüğümüzde esneklik, maliyet avantajı, yedeklilik, parallel işleme ve hız gibi önemli kazançlar elde ediyoruz. Bu yapıda, “commodity” dediğimiz donanım yapılarını, açık kaynak kodlu yazılımları veya yine büyük üreticilerin optimize bir şekilde açık kaynak kodlu yazılımları içine gömerek ürettikleri “appliance” yapıları kullanma şansımız oldukça fazla.
Büyük veriyi genelde 3V ile açıklıyor konunun uzmanları. “Volume” olarak adlandırdıkları, verinin büyüklüğü. Şöyle bir örnek veriyorlar veri boyutu için: 2013 yılında 670 ExaBytes olan büyüklük, 2017’de 1 Zetta Byte’dan fazla hale geldi, 2023’de 7 Zetta Byte’dan büyük olacağı söyleniyor. “Velocity” dedikleri, veri oluşum oranıdır (veri oluşum hızıdır). Günümüzde veri büyüme oranı, yeni teknolojilerin, yeni ihtiyaçların bir sonucu olarak hızla artmaktadır. Diğer V ise “Variety”, yani verinin değişik formatlardaki çeşitliliği olarak ifade edilebilir: yapısal veriler, yarı-yapısal veriler, yapısal olmayan veriler, her taraftan bizi etkisi altına almaya çoktan başladı.
Büyük veri analizi, işimizle ilgili hiç bir veriyi kaçırmadan, bu verilerin analiz edilmesine imkan veren maliyet avantajlı yazılım ve donanımları kullanarak analiz yapıp, daha doğru kararlar alabilmemizi sağlaması ve sonucu olarakta elbette daha fazla para/prestij kazanmamıza neden olması, sosyal medya verileri, “transaction” lar, arşivlenmiş veriler üzerinde analitik yapmamıza imkan sağlaması ile günümüzün en popüler konularından birisidir. Şekil 3.’de anlatmaya çalıştığım olguyu, görsel olarak bulabiliriz. Mevcut veriyi, geçmişe dönük veriyi kullanabiliyoruz. İçimizde barındırdığımız veriye ek olarak dışarda bulunan bizi etkileyeceğini düşündüğümüz sosyal medya verilerini sürece dahil edebiliyoruz. Bu sayede veriler arasındaki ilişkiyi, birbirine olan etkisini görebiliyor sonucu olarakta pazar davranışını öngörebiliyor, karar mekanizmamızı destekleyecek, geliştirebilecek çıktılar üretebiliyoruz. Tüm bunları yaparkende maliyet avantajı yakalayabiliyoruz.

Şekil 3. Büyük veri analizi
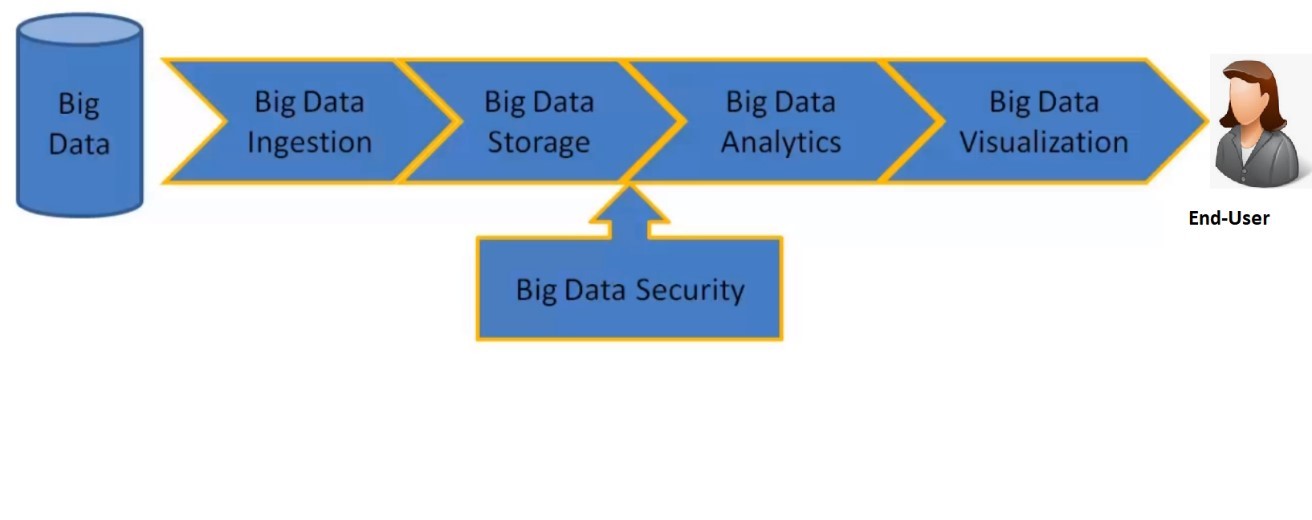
Büyük veri sürecinden bahsetmemiz önemli. En azından kendim için söyleyebileceğim, büyük resim, kavramları daha doğru anlamama yardımcı oldu.

Şekil 4. Büyük veri süreci
İlk aşamada, büyük verinin işlenebilir şekilde aktarımının gerçekleştirilmesi gerekir. Bütük veri kaynakları olarak, ilişkisel veri tabanlarını, arşiv dosyalarını, uygulamaların ürettiği log dosyalarını, klik verilerini (“click view”), işimizle ilgili müşterilerin gönderdiği verileri, sosyal medyadan gelen verileri, “web scraping” verilerini sayabiliriz. Verinin, büyük veri yapılarına aktarımı söz konusu olduğunda, “batch” ve “streaming” verilerin aktarım ihtiyacına göre kullanılabilecek araçlar farklılık göstermektedir. “Batch” veri dediğimizde, ilişkisel veri tabanlarından, arşiv dosyalarından, işimizle ilgili periyodik olarak gelen dosyalardan bahsederiz. Bu veriler, büyük veri sistemine, bir plan dahilinde “bulk” olarak yüklenebilir. Bu verilerin aktarımı için, sqoop, distcp gibi araçlar kullanabilir “streaming” veri dediğimizde ise, devamlı akan bir veriden (mesaj sistemlerinden, uygulama loglarından gelen veriler), twitter gibi sosyal medya verisinden bahsederiz. Veri gelir gelmez işlenmesi gereken verilerdir bunlar. Flume, Nifi, Flink gibi araçlar bu verilerin, büyük veri yapısına aktarımı için kullanılabilir.
Sqoop, Apache açık kaynak kodlu bir araçtır. İlişkisel veri tabanındaki verileri Hadoop’a aktarabilir. Distcp, Apache Hadoop’un içerisinde yer alan bir araçtır. Amazon S3’ten veriyi HDFS’e alabilir. Ayrı kurulumlar olarak yapılan HDFS’ler arası veri kopyalama işlemini yapabilir. Veriyi parallel olarak kopyalamak için “map-reduce” kullanır. Flume’da yine Apache açık kaynak kodlu bir araçtır. Çok büyük miktarlardaki veriyi taşıyabilir. Pek çok farklı kaynaktan gelen web loglarını, program loglarını HDFS’e aktarabilir. Sqoop, yapısal veri için kullanılırken, Flume, yapısal olmayan veri için kullanılır. Gelelim Kafka’ya. Oldukça popüler bir araç olan Kafka, sürekli olarak akan veriyi, mesajlar halinde işleyebilir. Saniyede milyonlarca mesajı işleyebilir. Veriyi, HDFS veya Cassandra’ya kopyalamak için bağlantı yapabilir (“connector” leri vardır). Apache Flink, isminde de geçtiği gibi, Apache açık kaynak kodlu bir araçtır. Akan veriyi, sürekli bir şekilde işleyebilir. Saniyede milyonlarca olayı (event) işleyebilir. Akış içerisinde bazı veriler, geç kalabilir. Eğer verinin geliş zamanına göre bir işlem yapılırsa, hatalı sonuçlar çıkabilir. Flink sayesinde, olay zamanı verinin bir parçası olarak veri yığınını (“batch”) tanımlamak için kullanılabilir. Nifi, Apache açık kaynak kodlu bir araçtır. GUI üzerinden veri akışını destekler. Mesajların işlenmesi için, GUI’yi kullanarak mesajları yönlendirebilir (veriyi, data ingestion’dan verinin işlenmesi noktasına yönlendirebilir). Kafka ve HDFS’e bağlantıları vardır. Veri akışını takip edebilir (data provenance).
Ne kadar çok araç var değil mi? Aslında ihtiyaca göre doğru aracın seçilmesi çok önemli. Bir kaç senaryo üzerinde konuşursak, bu araçların doğru kullanım alanlarını daha netleştirebiliriz diye düşünüyorum. Örneğin, yapacağımız bir senaryo için, faturalar Oracle veri tabanında tutuluyor olsun. Bu verileri işlemek için HDFS’e almamız gereksin. Veri formatı, ilişkisel veri tabanı olduğu için, Sqoop’u seçebiliriz. Sqoop, Oracle’a bağlanabilir. İkinci senaryomuzda, arşiv verisinin büyük bir dosya şeklinde Amazon S3 üzerinde durduğunu düşünelim. Verinin işlenmesi için HDFS’e alınması gereksin. Verinin formatı, regular dosya şeklindedir. Distcp aracını, S3’te olan veriyi HDFS’e kopyalamak için kullanabiliriz. Üçüncü senaryomuzda bir otomobil üreticisinin yeni bir ürün çıkardığını ve bu yeni ürünle ilgili “twitter” daki “tweet” verisine bakarak “sentiment” analizi yapmak istediğini düşünelim. Bu durumda, veri formatı, twitter’dan gelen sürekli formdaki tweet verisidir. Flume, data aktarımı için kullanılabilir. Nifi, “data provenance” için kullanılabilir. Dördüncü senaryomuzda ise pek çok farklı uygulamadan sürekli olarak gelen uygulama logları olsun. Bu durumda verinin türü, uygulamalardan sürekli olarak gelen log mesajlarıdır. Kafka producer, mesajlardan sürekli bir akış oluşturmak için kullanılır. Nifi, mesajları işlemek için kullanılabilir. Bu yazdıklarımızı, Şekil 5’de görsel olarak irdeleyebiliriz.

Şekil 5. Data aktarım araçları.
Büyük veri sürecindeki ikinci adımın (big data storage) detayına girebiliriz. Büyük verinin depolanması için kullanılan bileşenlerin belli karakteristikleri vardır. Dağıtık yapıda olmaları, veri replikasyonunu mümkün kılmaları, veriyi lokal olarak işleyebilmeleri, yükcek mevcudiyeti (High-Availability) sağlayabilmeleri, veriyi bölümleyebilmeleri, verinin denormalizasyonu olarak bu karakteristikler sıralanabilir. Bu noktada No-SQL’den bahsetmemiz gerekiyor. İlişkisel veri tabanı ilkelerini içermeyen tüm veri tabanları için kullanılan bir kavramdır. HDFS, Hadoop Distribute File System’in kısaltmasıdır. Veri bloklara bölünerek depolanır. Tanımlı replikasyon sayısı 3’tür. Master-Slave mimarisine göre çalışır. Namenode, master üzerinde çalışan prosestir. Datanode, her worker node üzerinde çalışır. Ikinci namenode, opsiyoneldir. Namenode metadatasını yedekler. Şekil 6’da HDFS’in çalışma prensibinin özetini görebiliriz.

Şekil 6. HDFS mimarisi
Büyük veri sürecinin ikinci aşamasında kullanılan bileşenlerden birisi HBase’dir. HBase, Apache açık kaynak kodlu bir araçtır. No-SQL veritabanıdır. “Transaction”ları desteklemez. Büyük veri tabanlarını destekler ve ölçeklenebilirdir. Kolumnar yapıda dağıtık bir veri tabanıdır. SQL’i desteklemez. Kendine ait sorgulama formatı vardır. Cassandra, Apache açık kaynak kodlu bir veri tabanıdır. Hatalara karşı çok yüksek toleransa sahiptir (No Single Point of Failure). Ring mimarisine sahiptir. Gerçek zamanlı okuma ve yazma yapar. Key-value veri tabanı olarak isimlendirilir. Doğrusal olarak ölçeklenebilir. Birden fazla veri merkezinde yedekli yapıda çalışabilir (Şekil 7). Eğer hızlı yazma işlemleri, full veya indexed search işlemleri varsa, veriyi sınıflandırmak gerekiyorsa, yüksek ölçeklenebilirlik isteniyorsa, hatalara karşı yüksek koruma ihtiyacı varsa, verinin denormalizasyonuna ihtiyaç varsa kullanılması uygun olur. Aggregations ve joins ler için uygun değildir. MongoDB yine büyük veri yapılarında kullanılabilir bir veri tabanıdır. Açık kaynak kodlu ve Döküman tabanlı bir veri tabanıdır. Yüksek ölçeklenebilirdir. No-SQL veri tabanıdır. Tablolar yoktur. Satır ve kolonlar yerine JSON nesneleri vardır. Hızlı veri erişimi sağlar. Impala, Apache Hadoop’un Cloudera dağıtımıdır. Ölçeklenebilir SQL ajanına sahiptir. SQL’i destekler. Gerçek zamanlı işleme yapabilir. Veri, HDFS ve HBase de depolanabilir. UDF’i destekler.
İkinci aşama ile ilgili hatırlanması gereken önemli bilgiler:
Büyük verinin dağıtık depolama ortamına ihtiyaç duyduğu,
Hatalara karşı yüksek korumaya gereksinim olduğu,
No-SQL’in ilişkisel veri tabanı kurallarını takip etmediği,
HDFS’in hacimli okuma operasyonlarında hız sağladığı,
Cassandra’nın “No Sigle Point of Failure” özelliğinde bir veri tabanı olduğu,
HBase’in yüksek miktardaki veriyi gerçek zamanlı işleyebildiği,
olarak sıralanabilir.

Şekil 7. Apache Cassandra mimarisi
Yazımın bu 1. bölümünde, büyük verinin neyi tanımladığından genel olarak bahsettim, büyük veri süreçlerini irdeleyerek ilk ikisi (ingestion ve storage) hakkında detaylı bilgiler aktarmaya çalıştım. İkinci bölümde, büyük veri sürecinin kalan üç önemli bileşeni ( analytics, visualization ve Security) üzerinde konuşmayı planlıyorum.
Asiye Yigit – 11 Kasım 2018
Kaynakça:
Ganapathi Devappa– Big Data Specialist – Big Data for Managers – Udemy Course