Merhaba;
Yazımın birinci bölümünde, büyük verinin tanımından, karakteristiklerinden bahsetmiştim. Büyük veri süreçlerini irdeleyerek ilk ikisi (“ingestion” ve “storage”) hakkında detaylı bilgiler aktarmıştım. İkinci bölümde, büyük veri sürecinin kalan üç önemli bileşeni ( analytics, visualization ve security) üzerinde konuşmayı planlıyorum demiştim. Gelin birlikte büyük veri sürecine kaldığımız yerden devam edelim.
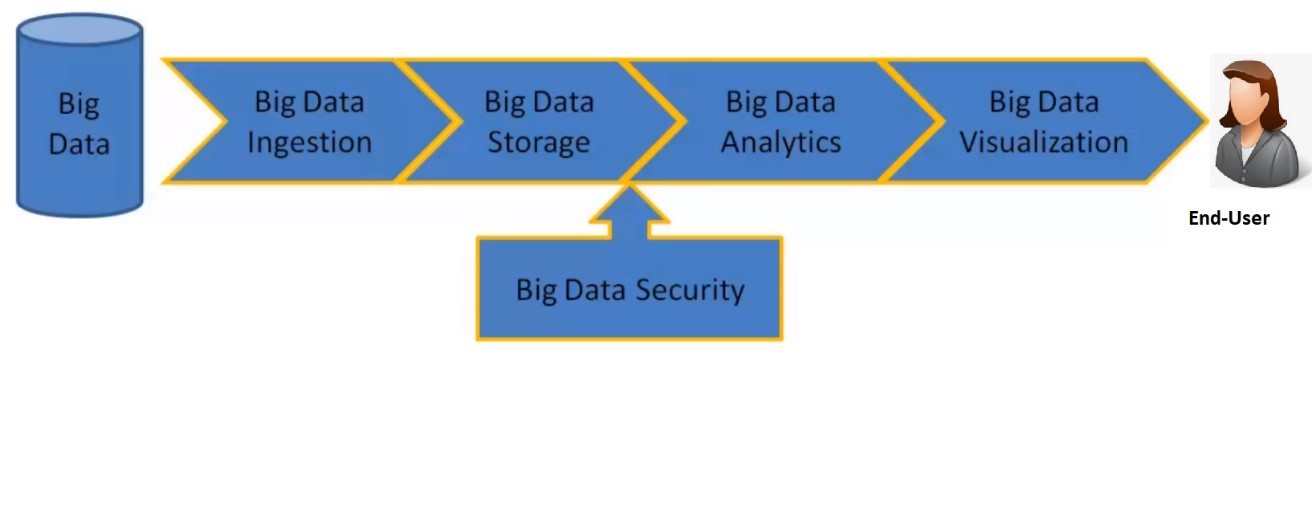
Büyük veri sürecini gösteren Şekil 1 üzerinden, kalan bu üç süreci detaylı irdeleyelim.
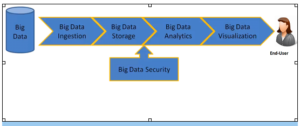
Şekil 1. Büyük veri süreci
Analitik sürecinden başlamak istiyorum. Birinci bölümden hatırlayacağımız gibi, büyük veri boyutsal olarak oldukça yüksek değerlere sahiptir. Dolayısıyla, büyük veri çözümlerinde dağıtık bir analitik süreci işin içerisinde olmalıdır. Yani tek bir sunucu kullanarak büyük veriyi analiz etmeniz imkansıza yakındır diyebiliriz. Büyük veri ile sadece tahmini bir analitik (ne olacak sorusunun cevabını bulmaya yarayan analitik) yapmazsınız aynı zamanda belirli aksiyonların alınmasını öneren “prescriptive” analitikte (ne yapılmalı sorusuna cevap bulmaya çalışan analitik) yapabilirsiniz. Büyük verinin analitik çalışmalarının çoğunluğunda, verinin transformasyonu gereklidir. Bu süreçte veriyi filtrelemeniz, veriyi farklı bir formata dönüştürmeniz, bazı durumlarda kelimeleri sayılara, sayıları kelimelere çevirmeniz gerekebilir. Pek çok veri transformasyon aracı vardır. Hadoop’un bir parçası olan Map-Reduce bu araçlardan biridir. Map-reduce, dağıtık haritalama ve özetleme fonksiyonları sunar. Pig ve Hive, Hadoop üzerinde çalışır. Java’da programlama yerine yüksek seviyeli programlama için kullanılır. Spark, Map-Reduce’ın sağladığı transformasyon özelliğinden daha fazlasına sahiptir ve daha hızlıdır. “stream” veride işleyebilir. No-SQL veri tabanları, transformasyon için betikler sağlar. Flink, storm, stream sets “stream” veri işleme araçları, java gibi programlama dilleri kullanarak büyük veri üzerinde manipülasyon yapma imkanı sağlar.
Bir kaç örnek üzerinden gidersek, anlaşılabilirliği artırabiliriz diye düşünüyorum. Örneğin, bir perakende firması, 100$’lardan fazla alış veriş yapan müşterileri filtrelemek ve lokasyonlarına göre gruplamak için “Map-Reduce” kullanabilir. “Map” fonksiyonu, kayıtları filtrelemek için kullanılırken, “reduce” fonksiyonu, lokasyona göre gruplama yapmak için kullanılır. Milyonlarca müşteri verisi, dağıtık işleme ile analiz edilebilir. Örneğin bir araç üreticisi, model yorumlarıyla ilgili “tweet” verisini filtreleyebilir, negatif hissiyat (“sentiments”) içeren “tweet” leri toplayabilir. “Map” fonksiyonu modele göre, “tweet” leri filtreleyebilir, hissiyat bilgilerini üretebilir. Ardından, “reduce” fonksiyonu, hissiyat kelimelerine göre gruplama yapabilir. Yine bir ürün üreticisi, ürünleriyle ilgili iç müşterilerden gelen geri beslemeleri, ürünlerle ilgili “tweet” yorumlarını eşleştirmek istesin. “Map” fonksiyonu, iç veri ile “tweet” yorumlarını birleştirirken, “reduce” fonksiyonu sonuçları toplamak için kullanılır. Bir kredi kart firması, şüpheli işlemleri filtrelemek ve kaçak analizi için kaçak yönetimi birimine daha detaylı analiz için bu verileri iletmek istesin. “Map” fonksiyonu, şüpheli işlemleri filtrelemek için kuralları uygular.
“Pig”, birden fazla ziyaret edilen web sayfalarını filtrelemek için kullanlabilir. Hive’i SQL’in bir alt seti gibi düşünebiliriz. Bu nedenle veri üzerinde, “selects”, “join”, “group by”, “sum”, “count” gibi işlemleri yapabiliriz. Spark’ı, makine öğrenme algoritmalarını uygulamak için kullanabilirsiniz. “Spark” ile, satın alma davranışına göre müşteri segmentasyonu yapabilirsiniz. Kar marjine göre, ürün segmentasyonu yapabilirsiniz. Sezona, çevresel faktörlere göre, ürün satışlarını tahminleyen bir model inşa edebilirsiniz.
“Storm”, akan veriyi işlemek için kullanılır. Pek çok sistemden gelen log mesajlarını, gerçek zamanlı olarak alıp, “parse” ederek, HDFS’e “Hive” tabloları şeklinde yazar. “Storm”, web klik verilerini alarak parallel olarak işleyebilir. Mesela, kredi kart işlemlerini gerçek zamanlı olarak alıp, şüpheli işlemleri belirlemek için parallel olarak işleyebilir. Yine, taşıyıcı bir firma GPS üzerinden gerçek zamanlı olarak araçlarıyla ilgili verileri alarak, bu veriler üzerinde “Storm” kullanarak araçların gideceği yolları optimize edebilir. “Storm”, “spouts” olarak isimlendirilen prosesi kullanarak, “kafka messages” da dahil olmak üzere dış sistemlerden veriyi alır ve “bolts” prosesini kullanarak veriyi işleyebilir. Ek olarak veriyi, HDFS’e de yazabilir. “Stream Sets”, akan veriyi işleyen diğer bir araçtır. “twitter” dan veriyi almak için kullanılır.
Büyük veri analizlerinde çok yoğun olarak kullanıldığı için AI’dan da bahsetmem gerekiyor. AI, makinelerin deneyimlerle öğrenmesini mümkün kılan bir teknolojidir. AI ile ilgili özellikle stranç oynayabilen bilgisayarları, kendi kendine giden araçları çok iyi biliyoruz. AI, çok geniş çaplı bir çalışma alanı sunuyor. Pek çok teknoloji, teori ve metod içeriyor. AI’in içerisinde yer alan alt ana başlıkları aşağıdaki gibi sıralayabiliriz.
Makine öğrenmesi (“machine learning”): Analitik model geliştirmeyi otomatik hale getirmek için kullanılır. Gizli kalmış bilgileri ortaya çıkarmak için, nöron ağlar, istatistik, yöneylem araştırması (“operations research”), fizik gibi teknolojileri kullanır.
Nöron ağlar (“neural network”): Nöronlar gibi birbirine bağlı birimlerle bilgiyi işleyen bir tür makine öğrenmesidir. Dışardan gelen girişlerle beslenir ve bilgi birimler arası iletilir.
Derin öğrenme (“deep learning”): Çok katmanlı işleme birimlerinden oluşan çok büyük nöron ağları kullanır. Bu öğrenme, hesaplama gücündeki teknolojik gelişimi kullanır. Aynı şekilde geliştirilmiş öğrenme teknikleri sayesinde, büyük miktarlardaki veri içinde kompleks desenleri öğrenebilir. Özellikle görüntü işleme ve konuşma metinleştirici uygulamalarında kullanım alanı bulur.
Bilişsel öğrenme (“cognitive learning”): AI’ın bir alt alanıdır. Makinelerle insana benzer etkileşimlerde bulunmayı sağlamak için geliştirilen bir teknolojidir. AI ve bilişsel öğrenmenin asıl amacı, bir makinenin, insanın görüntü ve lehçe anlama yeteneğini simüle edebilmesini ve tutarlı bir şekilde konuşmasını sağlamaktır.
Bilgisayarlı görme (“computer vision”): Bir fotoğrafda veya videoda ne olduğunu tanımak için derin öğrenme ve örüntü tanıma (“pattern recognition”) teknolojilerine güvenir. Bir makine, görüntüleri işleyebildiği, analiz edebildiği ve anlayabildiği zaman, görüntüleri ve videoları gerçek zamanlı olarak yorumlayabilir ve gereken aksiyonların alınmasını sağlayabilir.
Doğal dil işleme (“natural language processing”): Bilgisayarların, insan lehçesini, konuşmasını analiz edebilmesi, anlaması ve işleyebilmesi yeteneği olarak ifade edilebilir. NLP’deki asıl gaye, insan ve bilgisayarların günlük konuşma dilini kullanarak birbirleriyle iletişim kurabilmesini sağlamaktır.
Makine öğrenmesinin, öğrenebildiğini ve veriyi kullanarak tahminler yapabildiğini söyleyebiliriz. Makine öğrenme tekniklerine birkaç örnek vermek istiyorum. Sınıflama (“classification”), veriyi belli kategorilere ayırır. Örneğin, verilen borç için kategoriler, “very high”, “high”, “medium”, “low”, “very low” olabilir. Geçmişte bu şekilde kategorilere ayrılmış verilerden, makine öğrenmesi eğitilebilir. “Regression” tekniği, geleceğe dair tahminlemeyi yapmak için kullanılır. Örneğin, bir üretici, tarihsel verileri kullanarak gelecek 6 ay için ürün satışlarını tahmin etmek isteyebilir. Normal koşullarda geçmişe dair verinin %80’ı eğitim için kullanılırken kalan %20’si test için kullanılır. “Regression” modeli, eğitim verisine göre inşa edilir. Inşa edilen modelin doğruluğu, test verisi ile kontrol edilir. Modelin doğruluğundan emin olduğunuzda modeli gerçek dünya için kullanabilirsiniz. “Association” model, birlikte gerçekleşecek olayları belirlemek için kullanılır. “Market basket” analizi en yaygın örneklerinden biridir. “Clustering” modeli, benzerliklerine göre veriyi, alt kümeler şeklinde gruplamak için kullanılır. “Clustering” modeli, gözetimsiz öğrenme türüdür. Şekil 2’de “K-means cluster” için bir örnek görebilirsiniz. Bu örnekte, K=4’dür. 4 farklı “cluster” görmektesiniz.
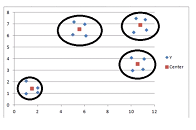
Şekil 2. “4-means” cluster
En önemli sorumuz geliyor. Büyük veriden elde ettiğiniz görüşleri, aksiyonlara nasıl dönüştüreceksiniz? Büyük veriden elde ettiğimiz görüşlere göre alabileceğimiz aksiyonlar neler olabilir?
Süreçlerin iyileştirilmesi (süreçlerdeki darboğazların bulunarak iyileştirilme sağlanması.)
Ürünlerin geliştirilmesi (müşteri eğilimlerini, gelen geri beslemeleri kullanarak ürüne yeni özellik eklenmesi veya bazı özelliklerin üründen alınması.)
Yeni ürün önerileri (insanların rakip firmaların ürünlerinde bulduğu eksikleri tweet verisinden okuyarak, tüm bu eksikleri tamamlayan yeni bir ürün önerisi yapılabilir.)
Yeni satış kanalları (eğilimler takip edilerek yeni satış kanalları bulunabilir. Yeni satış kampanyaları başlatılabilir.)
Uyumluluk birimlerine veri sağlanması (bu şekilde pahalı cezaların önüne geçilebilir.)
Tedarik birimine uyarıların gitmesi (talep ve stok tahminlerine göre tedarik birimine uyarıların gitmesi.)
Büyük veri analizi tamamlandıktan sonra sonuçları görselleştirme araçlarıyla irdelerseniz daha net görüşleri kolaylıkla üretebilirsiniz. Örneğin, analiz sonrası çıkan verileri Şekil 3 gibi grafiğe döktüğünüzde, dışarda kalan noktaları, anormallikleri daha kolay inceleyebilirsiniz.
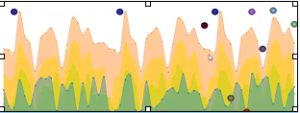
Şekil 3. Büyük veri analiz sonrası çıktıların görselleştirilmesi
Tableau, Qlikview, Zeppelin, R, Pentaho gibi araçlarla çıktıları görselleştirebilirsiniz. Zeppelin, Apache açık kaynak kodlu bir araçtır. Spark, Python, R gibi araçlarla bağlantı kurabilir. “Java script chart” larıda, java veya herhangi bir programlama dilinden verileri alabilir ve etkileşimli grafikler oluşturabilir. Geleneksel olarak devamlı kullandığımız grafikleri biliyoruz: pie, bar, line grafikleri bunlara örnek verilebilir. Büyük veri görselleştirmede genellikle heat haritaları, kelime bulutları, sembol haritaları kullanılır.
Büyük veri güvenliğinde en önemli istek, büyük veri sürecindeki her aşamada verinin güvenliğini sağlamak ve yalnış ellere geçmeyeceğini garantilemektir. Büyük veri güvenliğinde olmaz ise olmaz protokollerin başında elbette Kerberos gelir. MIT tarafından kimlik doğrulama sağlamak için geliştirilmiştir. Büyük veriye güvenli bağlantı sağlamak için kullanılır. Apache Knox, Apache açık kaynak kodundan gelen bir güvenlik aracıdır. Hadoop servisleri için, http-proxy gateway sağlar. Apache Ranger, Apache’nin diğer açık kaynak kodlu bir projesidir. Hadoop ekosistemi ( Hadoop, Hive, HBase, Spark gibi) için güvenlik sağlar. Rol ve nitelik bazlı yetkilendirme sağlar. Apache sentry, diğer bir açık kaynak kodlu projedir. Rol tabanlı kimlik doğrulama ve yetkilendirme sağlar. Daha granüler düzeyde erişimleri kontrol eder. HDFS üzerinde spesifik bir dizine veya Hive üzerinde spesifik bir tabloya ulaşım için gerekli kuralları tanımlar.
Büyük veri ile ilgili ikinci bölümüde bu şekilde tamamlıyorum. Büyük veri sürecinde rol alan tüm bileşenlerden kısaca bahsetmeye çalıştım. Umarım bu bilgileri faydalı bulursunuz.
Asiye Yigit – 2 Aralık 2018 Pazar
Kaynakça:
Big Data for Managers – Udemy ( Ganapathi Devappa)
https://www.sas.com/en_us/insights/analytics/what-is-artificial-intelligence.html